Enterprise Intelligent Knowledge Base Solution
Business Scenarios and Pain Points
Pain Points
01

Low Knowledge Reliability and Usability
As LLM adoption grows, enterprises need more accurate and consistent knowledge results. Yet current knowledge systems still suffer from scattered sources and inconsistent standards, with weak verification and traceability for retrieval and generated results.
Pain Points
02

Weak Knowledge Accumulation and Reuse
Although technology keeps improving, much internal experiential and tacit knowledge is still not structured. It remains scattered across documents and individuals, limiting knowledge assetization and large-scale reuse.
Pain Points
03

Weak Business Support and Limited Depth
Current knowledge applications focus mostly on retrieval and Q&A and are not tightly connected to business workflows, making them hard to use for complex analysis and decision-making.
Pain Points
04

Rising Governance and Compliance Pressure
As data volume and usage grow, the cost of knowledge governance and operations keeps rising. At the same time, multi-system data exchange increases demands on permissions, security, and compliance auditing.
Solution Details
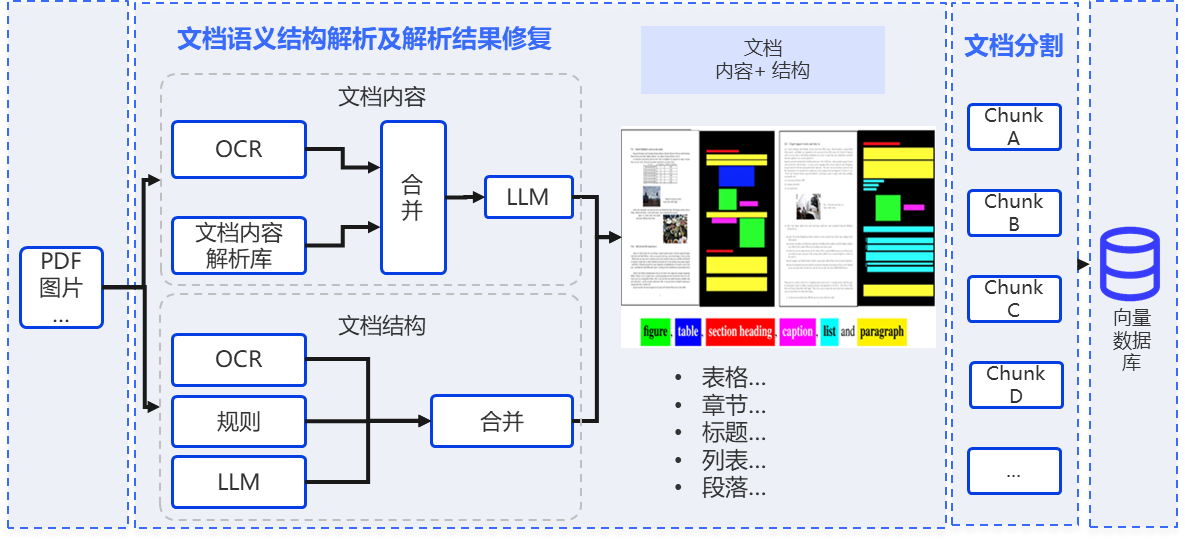
Multimodal Parsing and Structured Understanding
With document parsing and result repair, it improves recognition accuracy and parsing stability for unstructured documents, accurately extracting and restoring tables, charts, and multi-level headings for better downstream retrieval and knowledge processing.
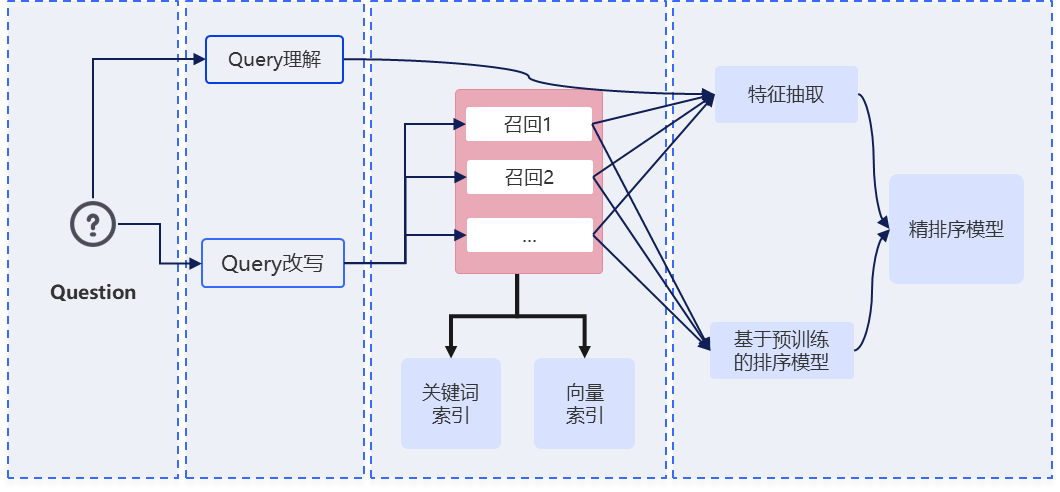
Enterprise-Grade High-Precision Search
It builds a retrieval optimization system covering query understanding, multi-path recall, and fine ranking. Through entity parsing, correction, semantic rewriting, and query expansion, it improves search expression quality and overall result accuracy.
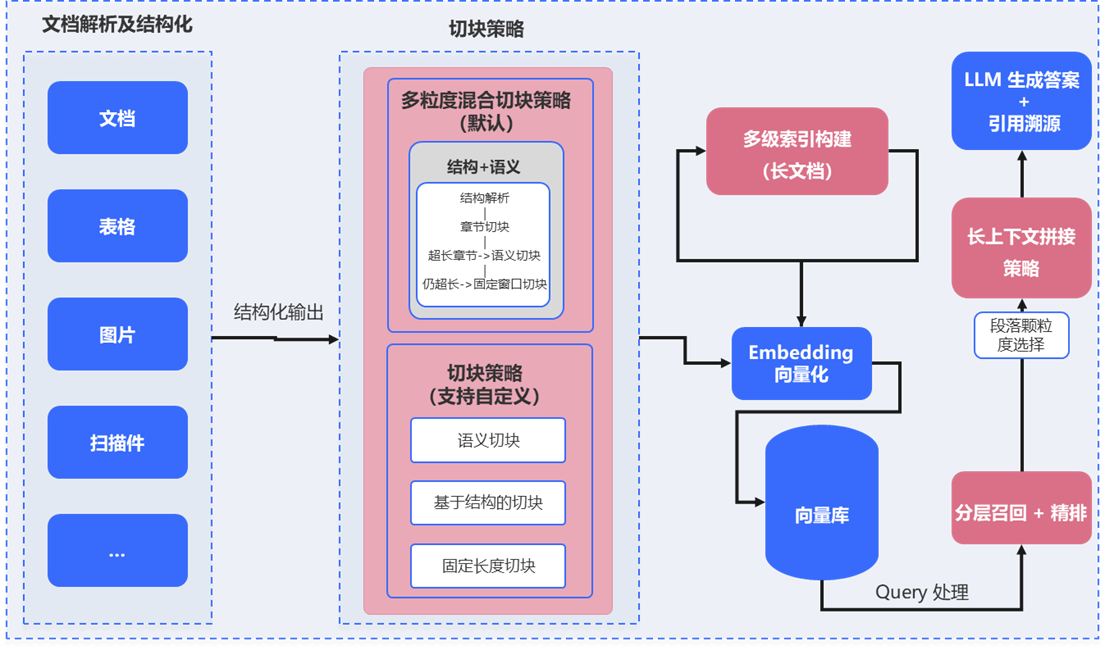
Long-Document Understanding and Efficient Retrieval
For complex long documents and knowledge retrieval, it combines structure parsing, chunking optimization, and layered indexing. Multi-level indexes and long-context assembly help efficiently integrate and retrieve highly relevant information.
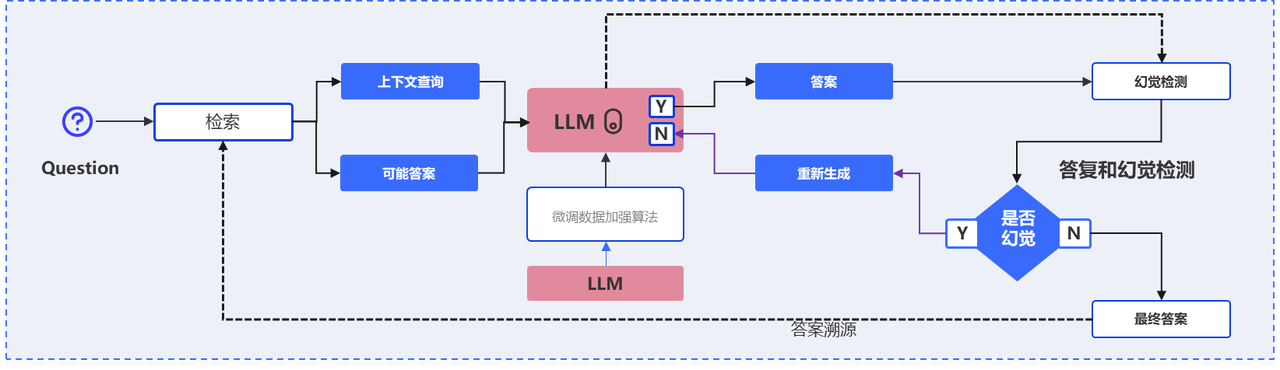
Trusted AI Q&A and Hallucination Control
The model answers based on retrieval and its own knowledge, while an abstention mechanism lets it refuse when information is insufficient or uncertain. Hallucination detection and iterative optimization further improve truthfulness, accuracy, and reliability.
Business Value

Better Knowledge Access and Analysis
By combining deep search and knowledge Q&A, it supports cross-source retrieval and semantic understanding, improving the completeness and accuracy of information access while reducing filtering costs.

Stronger Content Production and Professional Output
With knowledge-base support for reports, plans, and policy documents, it improves output efficiency and consistency, reduces repetitive work, and ensures quality and standardization.

Knowledge Governance and Organizational Accumulation
Centered on full-lifecycle knowledge management, it strengthens accumulation, updates, and reuse, promotes standardized application across business processes, and builds sustainable knowledge assets.
Application Cases
Related Products
Mengzi Models
Langboat's in-house developed large language model, capable of handling multilingual, multimodal data, and supporting various text understanding and text generation tasks. It can rapidly meet the requirements of different domains and application scenarios.
Langboat Smart Knowledge Base
Provide intelligent AI search, AI-assisted writing, and other functions to help enterprises rapidly build their own secure and reliable knowledge mid-platform.
Products
About Us
Business Cooperation Email
Address
Floor 16, Fangzheng International Building, No. 52 Beisihuan West Road, Haidian District, Beijing, China.
© 2023, Langboat Co., Limited. All rights reserved.
Large Model Registration Code:Beijing-MengZiGPT-20231205
Business Cooperation:
bd@langboat.com
Address:
Floor 16, Fangzheng International Building, No. 52 Beisihuan West Road, Haidian District, Beijing, China.
Official Accounts:

© 2023, Langboat Co., Limited. All rights reserved.
Large Model Registration Code:Beijing-MengZiGPT-20231205


