企业智能知识库解决方案
业务场景和痛点
痛点
01

知识可信性与可用性不足
在大模型广泛应用背景下,企业对知识结果的准确性与一致性要求显著提升。然而,现有知识体系仍存在来源分散、标准不统一等问题,检索与生成结果缺乏有效校验与溯源机制,难以满足高要求业务场景的使用标准。
痛点
02

知识沉淀与复用能力不足
尽管技术能力不断提升,企业内部大量经验性与隐性知识仍未实现结构化沉淀,分散于各类文档与个体经验中,缺乏统一管理与持续演进机制,制约知识资产化与规模化复用。
痛点
03

业务支撑能力不足,应用深度有限
当前知识应用多集中于检索与问答层面,与具体业务流程结合不够紧密,难以支撑复杂场景下的分析与决策需求,尚未形成贯穿业务全流程的有效支撑能力。
痛点
04

治理成本与合规压力持续上升
在数据规模与应用范围不断扩大的背景下,知识治理与运营成本持续增加;同时,多系统数据交互带来的权限控制、数据安全与合规审计要求进一步提高,对企业整体管理能力提出更高要求。
具体解决方案
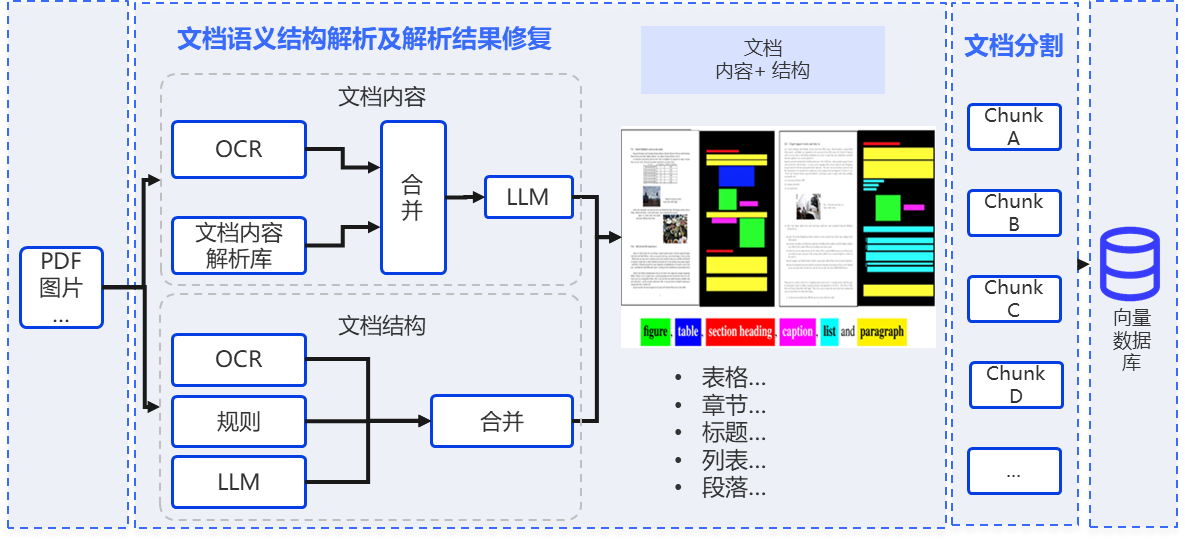
多模态文档解析与结构化理解能力
基于文档解析与结果修复机制,提升非结构化文档的识别准确性与解析稳定性,实现对表格、图表及多级标题结构的精准抽取与还原。结合多粒度分块策略与版式语义信息融合,优化内容切分与上下文关联,并针对复杂文档结构进行专项优化,整体提升文档理解能力,为下游检索与知识处理提供高质量数据基础。
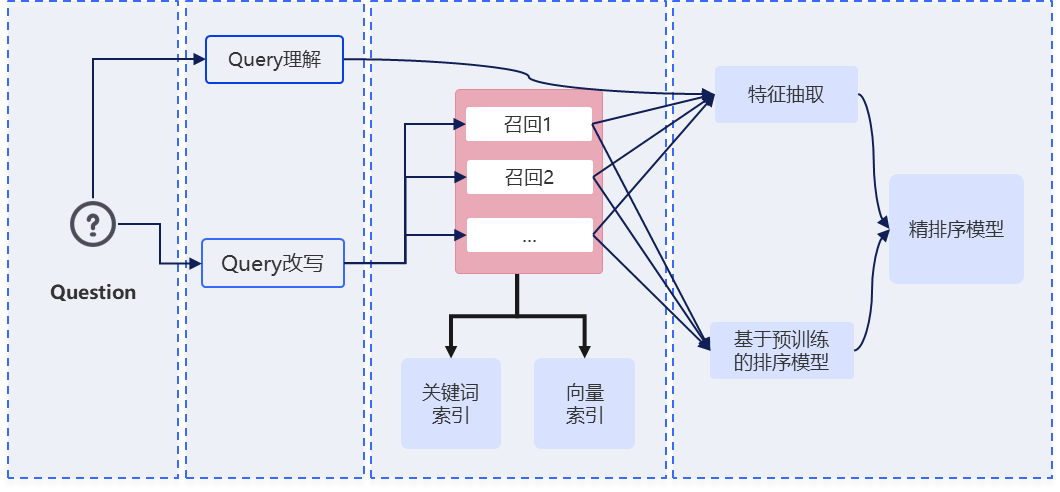
企业级高精度搜索与检索效果提升
构建覆盖Query理解、多路召回与精排序的检索优化体系。通过实体解析、纠错与语义改写,结合查询扩展机制提升检索表达质量。在召回层融合语义向量与关键词策略,兼顾语义相关性与专业匹配。在排序层基于多特征融合的梯度提升决策树模型进行统一建模,实现结果的精细化排序,整体提升检索效果与结果准确性。
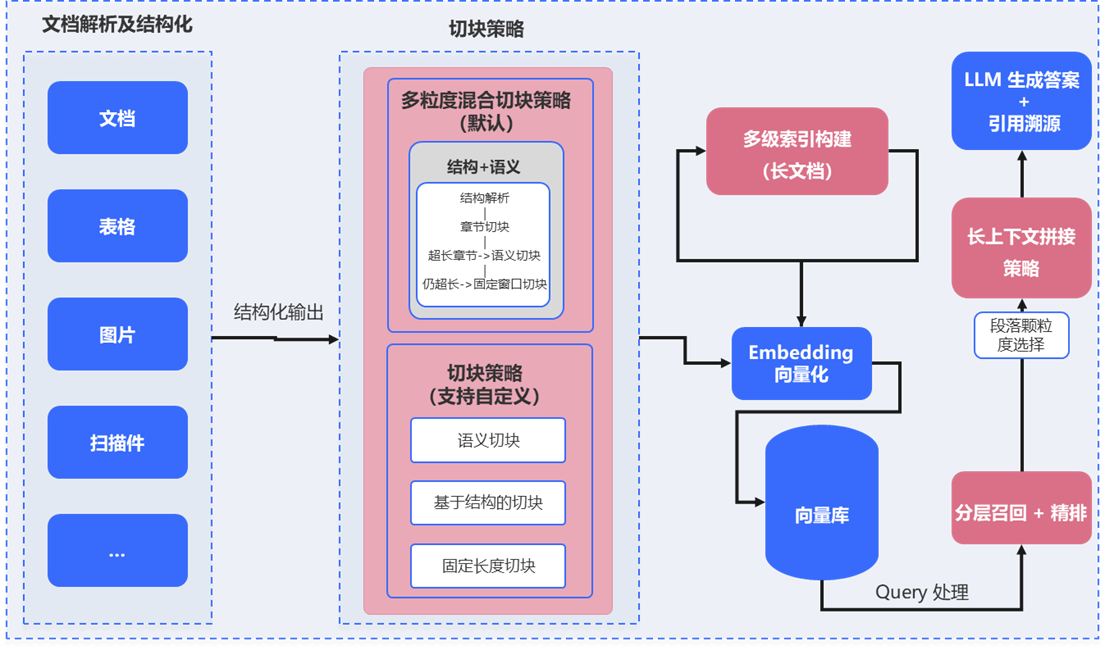
长文档理解与高效检索处理能力
针对复杂长文档与知识检索,构建结构解析、切块优化与分层索引的整体能力。基于章节进行切块,对超长或结构不完整内容采用语义边界识别与滑动窗口的多粒度混合策略,保障语义完整性与上下文连续性,并支持自定义配置。通过文档级、章节级和内容块级的多层索引,结合长上下文拼接与摘要压缩,实现高相关信息的高效整合与检索。
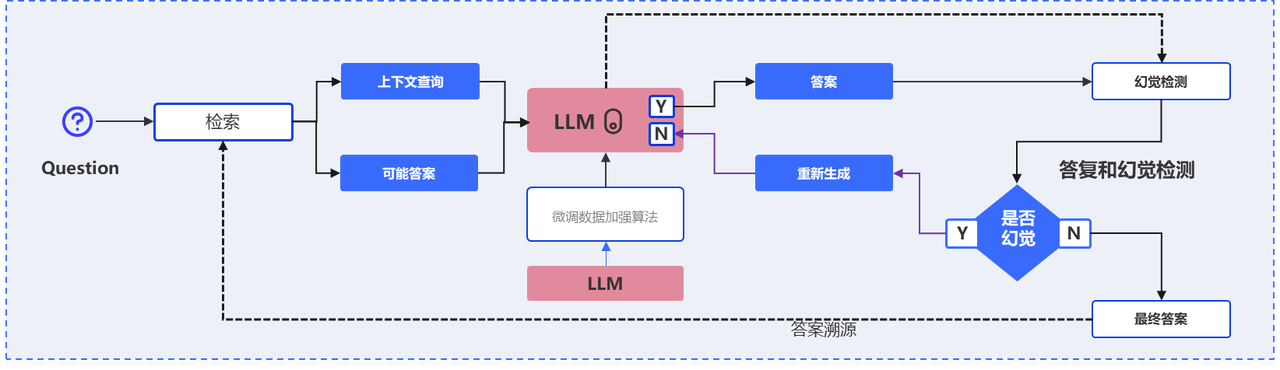
可信AI问答与幻觉检测增强
模型基于检索与自身知识进行回答,并结合自主拒识机制,在信息不足或不确定时主动拒答,避免错误输出;同时引入幻觉检测与迭代优化能力,对生成结果进行事实校验,一旦识别风险内容,自动改写指令并重新生成答案;结合微调策略,持续强化模型在“可答、准答、该拒则拒”方面的能力,从而显著提升复杂场景下问答结果的真实性、准确性与可靠性。
业务价值

知识获取与分析能力提升
整合深度搜索与知识问答能力,支持跨源数据检索与语义理解,能够对复杂问题进行关联分析与结果整合,提升信息获取的完整性与准确性。相较传统检索方式,显著降低信息筛选成本,提高知识使用效率。

内容生产与专业输出能力提升
基于知识库支撑各类报告、方案与制度类内容生成,提升专业内容产出效率与一致性,减少重复性工作,保障输出质量与规范性,满足多场景业务表达需求。

知识治理与组织能力沉淀
围绕知识全生命周期管理,强化知识的沉淀、更新与复用机制,推动知识在各业务环节中的标准化应用,提升组织协同效率,构建可持续演进的知识资产体系。
应用案例




