解决方案简介
智能投研解决方案
澜舟智能投研解决方案以自研孟子大模型为核心底座,兼容主流第三方大模型,依托澜舟智库、智会、智搭三大核心产品,覆盖投研“管、读、搜、问、写” 全流程业务场景。方案融合RAG多跳检索、多智能体、表格推理、多模态解析等技术,可实现多源投研数据统一管理、深度解析、智能问答、报告生成与会议智能化处理,有效破解数据孤岛、信息处理低效、决策支撑薄弱等行业痛点,为金融机构提供全链路、高可靠的智能投研赋能服务。
业务场景和痛点
痛点
01

知识深度不足
传统投研数据库已完成研报、纪要、资讯、公告等非结构化数据的收集和整理,但缺乏基于这些数据形成投研领域专业深度的知识整理和分析。
痛点
02

数据噪音难穿透
投研场景多源数据混杂冗余,传统方式无法穿透信息噪音、提炼核心驱动因素,易出现数据幻觉干扰投研判断与决策。
痛点
03

信息处理效率低
会议纪要整理、研报速读、投研报告撰写高度依赖人工,中英文信息脱水、核心数据提取耗时久,成果产出严重滞后。
痛点
04

决策支撑能力弱
缺乏智能选股、数据推理、策略生成能力,投研结论难以溯源,无法为投资决策与投顾服务提供高效、精准的支撑。
智能投研解决方案
基于语义理解和投研领域的知识扩充
基于孟子预训练模型技术体系,通过对海量金融领域专业基础语料的学习,针对研报、公告、舆情等数据,自动抽取有投研领域知识深度的问答对,丰富扩充投研信息数据库。
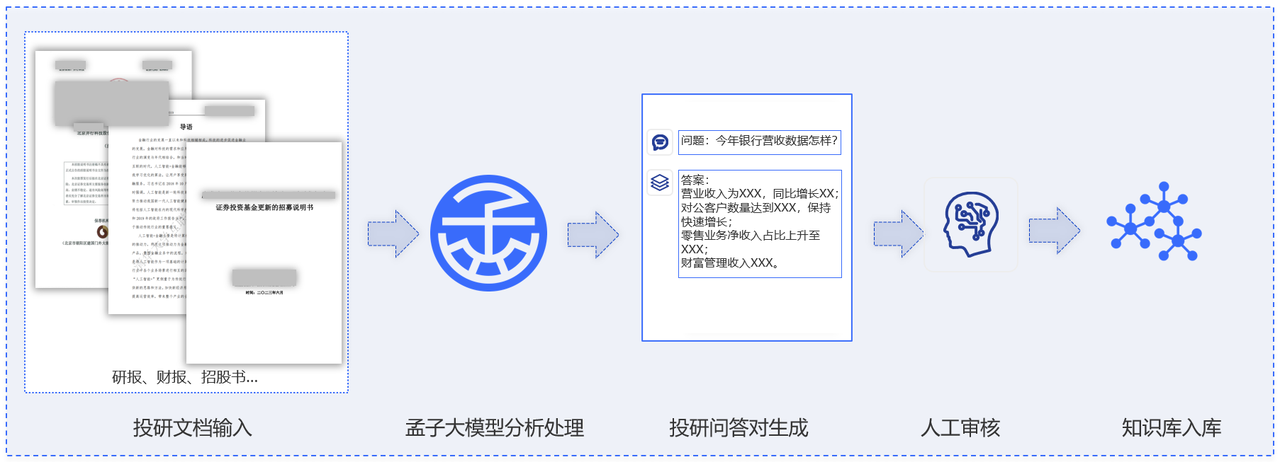
多源数据降噪穿透实现精准解析
通过对全行业金融数据与投研框架的学习,针对多源数据噪音问题,自动穿透信息干扰、提炼核心驱动因素,保障投研结论可溯源。

智能会议处理高效完成信息脱水
通过对金融会议、路演专业语料的学习,针对中英文会议资料,自动提取核心数据与问答对,生成标准化智能会议纪要。

智能决策引擎赋能投研服务
通过对投研选股、投研服务逻辑的学习,可针对策略生成、客户服务需求,自动构建决策引擎、输出投研报告与服务方案。
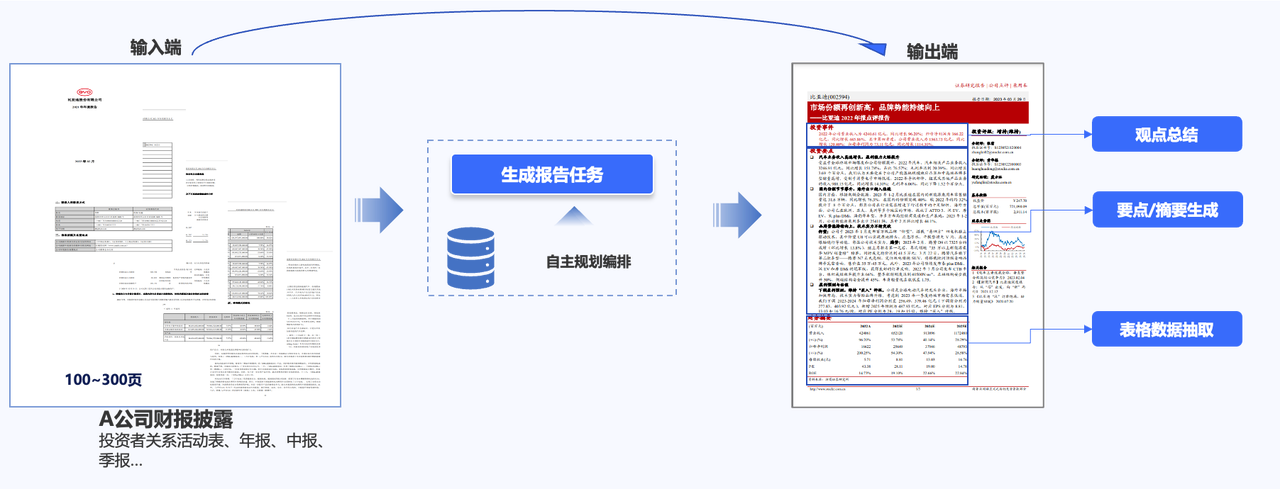
业务价值

提升投研知识库的分析能力
通过投研业务关注问题、业务知识细化分析,逐步提升大模型的投研知识积累,自动生成有业务深度的问题,方便用户快速分析提问,获取投研知识。

提升投研信息检索效率
将传统投研搜索耗时大幅缩短,检索效率提升 20 倍,助力投研人员极速定位核心信息,降低信息查找的时间与人力成本。

缩短投研成果产出周期
自动完成研报撰写、纪要生成、数据整理工作,投研业务流程耗时显著缩短,大幅提升投研成果输出与市场响应速度。
应用案例




