《自然语言处理技术最新进展》- 周明博士在第二届1024国际智能投研开发者大会做特邀报告
2021-10-24
引言#
前几年人工智能在感知智能方面进展迅速。而我们今天看到的一个明显趋势是 AI 正由感知智能快速向以自然语言处理(NLP)为核心的认知智能迈进。AI 正在从能说会看,走到能思考、回答问题,走到决策和推理。认知智能的应用例子比比皆是。例如,达到了接近人类水准的机器翻译已经在手机和桌面普遍使用,聊天机器人几乎可以通过图灵测试,搜索引擎得益于阅读理解以及预训练模型,搜索相关度大幅度提升,自动客服系统已经普及,知识图谱在金融等领域得到快速应用。都在推动产业发展。从大数据,到建立信息检索,到建立知识图谱,实现知识推理,到发现趋势,形成观点和洞见。AI正在深刻推动产业的发展。
在这样的形势下,澜舟科技公司提出了孟子新一代认知服务引擎研究计划,目标是研究认知智能的核心任务,用认知智能技术促进行业数字化转型。我们研制了孟子轻量化预训练模型,以及建立在其上的先进的机器翻译、文本生成和行业搜索引擎,并通过开源、SaaS 和订制等方式赋能行业客户。
下面将结合我们的研发实践,介绍 NLP 技术的最新进展,包括在金融领域的应用:金融预训练模型、金融翻译和金融搜索引擎。
预训练模型#
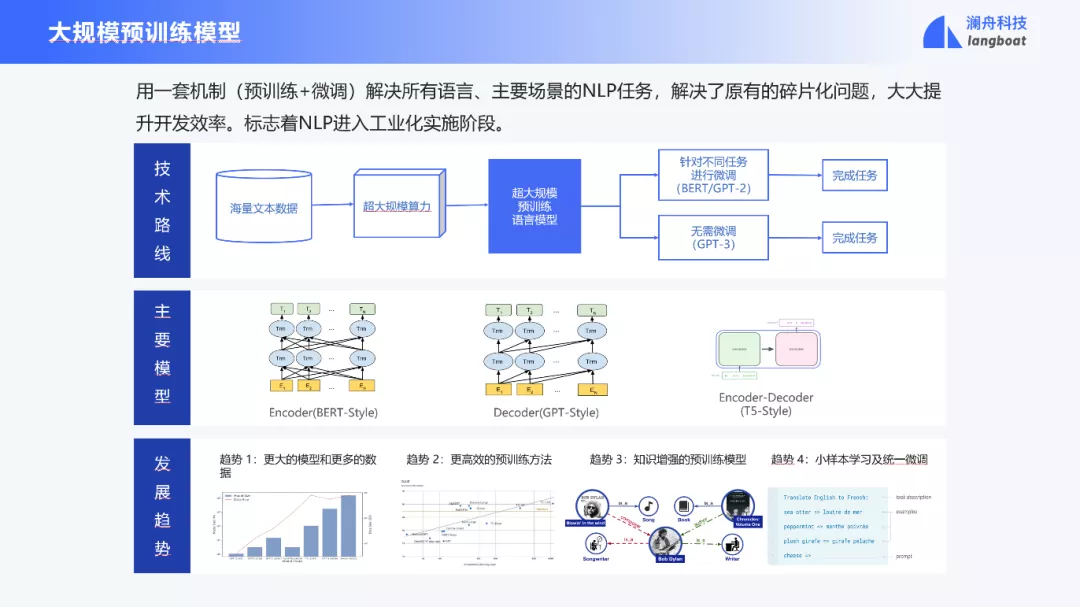
预训练成为了认知智能的核心技术。2017年推出的Transformer催生了BERT、GPT、T5等预训练模型。这些模型基于自监督学习,利用大规模文本,学习一个语言模型。在此基础上,针对每一个 NLP 任务,用有限的标注数据进行微调。这种迁移学习技术实实在在地推动了 NLP 发展,各项任务都上了一个大台阶。更为重要的是,产生的预训练+微调技术,可以一套技术解决不同的NLP任务,有效地提升了开发效率。这标志着 NLP 进入到工业化实施阶段。
当前在预训练模型领域较为关注的研究重点包括:如何训练超大规模参数的模型,对已有模型架构的创新性研究、获得更加有效的训练方法和训练加速的方法。还有就是简化微调的步骤比如像 GPT-3 那样用一套提示机制来统一所有下游任务的微调。除此之外,多模态预训练模型和推理的加速方法也是目前的研究焦点。
人们普遍认为,在相同网络架构和训练方法下,模型层次增加、模型参数增加,能力就一定增强。增强的幅度越来越小。由于训练一个大模型代价很大,譬如 GPT-3 训练需要460万美金。加之大模型落地部署的代价也极大。虽然由于摩尔定律,硬件逐年价格下降1.5倍,运算能力提升1.5倍,但是模型每年增加至少7倍,硬件的能力赶不上模型规模的增长。还有在实际应用中要考虑部署的成本。在摩尔定律逐渐走向终结的今天,模型轻量化是必须要考虑的。轻量化有两个途径。一个是大模型经过蒸馏压缩成小模型,一个方向是直接研究轻量化模型。当然二者也可以融合,比如前者用来给后者做初始化。
基于这些考虑,我们开发了孟子预训练模型。它支持多种模型架构,轻量化模型,采用了知识图谱、语言学知识来增强,并且充分利用了领域数据、任务数据和多语言数据来增强。并且优化了微调效果。最近在中文预训练模型的评测中,以10亿参数的轻量化模型荣登分类、阅读理解和总榜的榜首。我宣布已经开源四个模型,支持通用和金融领域的语言和多模态的应用。
孟子轻量化模型基于“小”、“精”、“快”、“专”的思想研发,追求更实际的商业用途。在今年 7 月,我们的孟子模型以 10 亿参数规模,超过国内众多大厂的百亿乃至千亿规模的模型,跻身 CLUE (中文语言理解测评基准)第一名。这证明了我们的研究方向的正确性。

为了回馈开源社区,进一步推动中文 NLP 领域的发展,我们最近开放了一系列孟子中文模型:
- Mengzi-BERT-base,参数量 110M,兼容 BERT 架构,利用语言学知识增强模型能力。适用于文本分类、实体识别、关系抽取等任务。
- Mengzi-BERT-base-fin,参数量 110M,基于 Mengzi-BERT-base 在金融语料上继续训练。适用于金融新闻分类、信息抽取、情感分析等任务。
- Mengzi-T5-base,参数量 220M,兼容 T5 架构,可以提升文本生成的可控性,优于 GPT 结构。适用于文案生成、新闻生成等任务。
- Mengzi-Oscar-base,参数量 110M,基于 Mengzi-BERT-base 的多模态模型。在百万级图文对上进行训练。适用于图片描述、图文互检等任务。
相关的文档和模型下载,请参考我们的 Github 项目:https://github.com/Langboat/Mengzi 。更多的技术细节,请参考我们的技术报告:https://arxiv.org/abs/2110.06696 。
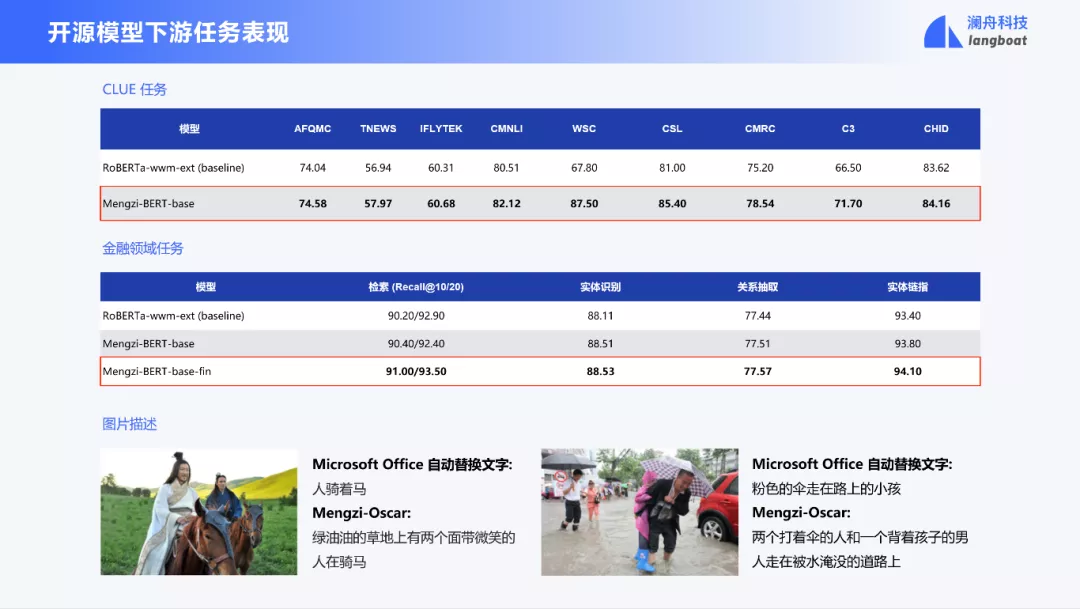
这是我们开源的模型的评测表现,可以看到,在 CLUE 任务和金融领域 4 个任务上,孟子模型优于现有的开源模型。在图片描述任务上,孟子模型相比于 Microsoft Office 自动替换文字,描述更准确,细节更丰富。
机器翻译#
机器翻译经历了基于规则的方法、统计机器学习和神经网络机器翻译三个阶段。近年来,随着深度学习技术的发展,基于神经网络的机器翻译系统取得了较大进步,在一些语言间,机器翻译的性能可比肩专业译员。神经机器翻译(Neural Machine Translation)是指直接采用神经网络以端到端方式进行翻译建模的机器翻译方法。神经机器翻译简化了统计机器翻译的中间步骤,采用一种简单直观的方法完成翻译工作:首先使用一个称为编码器(Encoder)的神经网络将源语言句子编码为一个稠密向量,然后使用一个称为解码器(Decoder)的神经网络从该向量中解码出目标语言句子,该模型通常称之为“编码器-解码器”(Encoder-Decoder)框架。近年来,以 LSTM 和 Transformer 为代表的神经机器翻译框架在性能上取得了显著提升,已被广泛应用在工业翻译平台。
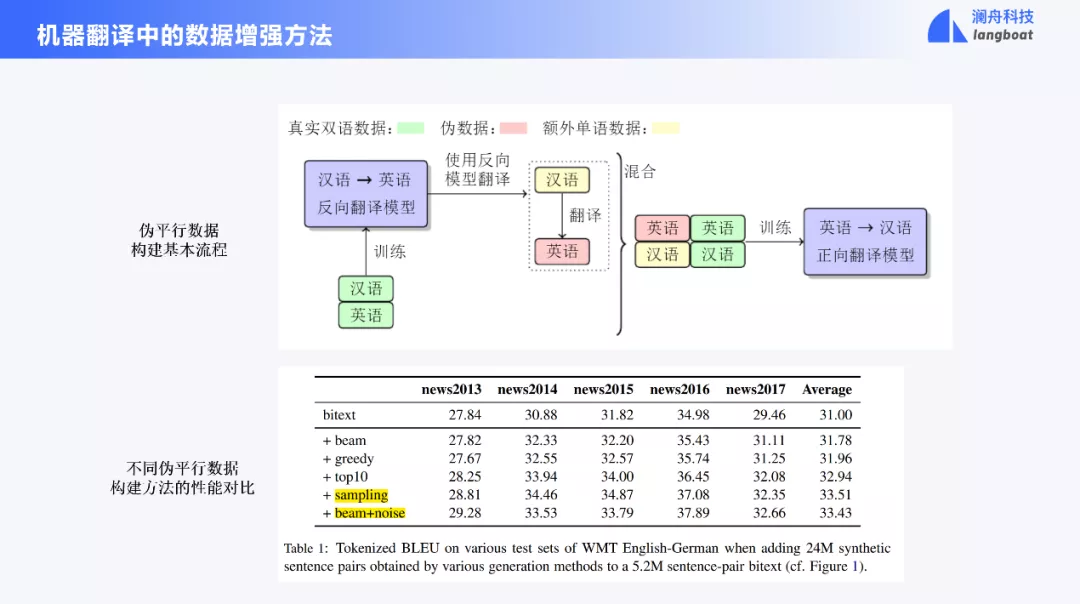
在现代人工智能系统中,核心算法+高质量数据是打造一个好的AI系统的双翼。构建一个高质量翻译模型,需要大量高质量双语平行句对,而人工构建这样的双语翻译数据,耗时耗力,短期很难实现。而互联网上的单语数据总是比双语数据容易获取,一个有效的方法就是利用单语数据增强翻译性能,常用的就是反向翻译技术(back-translation)。反向翻译技术中利用单语数据的方法可归纳如下:为了改进英汉翻译模型,我们先用汉英平行数据训练一个反向翻译模型(汉语翻译为英语),然后将大规模汉语单语数据翻译为英语,构建伪的英汉平行语料,用来训练英汉翻译模型。最终,我们把标准的翻译数据和生成的伪数据混合在一起训练英汉翻译模型。
由于自然语言表达的多样性,我们所使用的训练数据总是相对不足的,增大训练数据的多样性也是改进翻译模型性能的一个有效手段,相比于 Beam 和 Greedy 搜索算法,利用 Sampling 和 Beam+noise,增加训练数据的多样性,可以进一步改进性能。
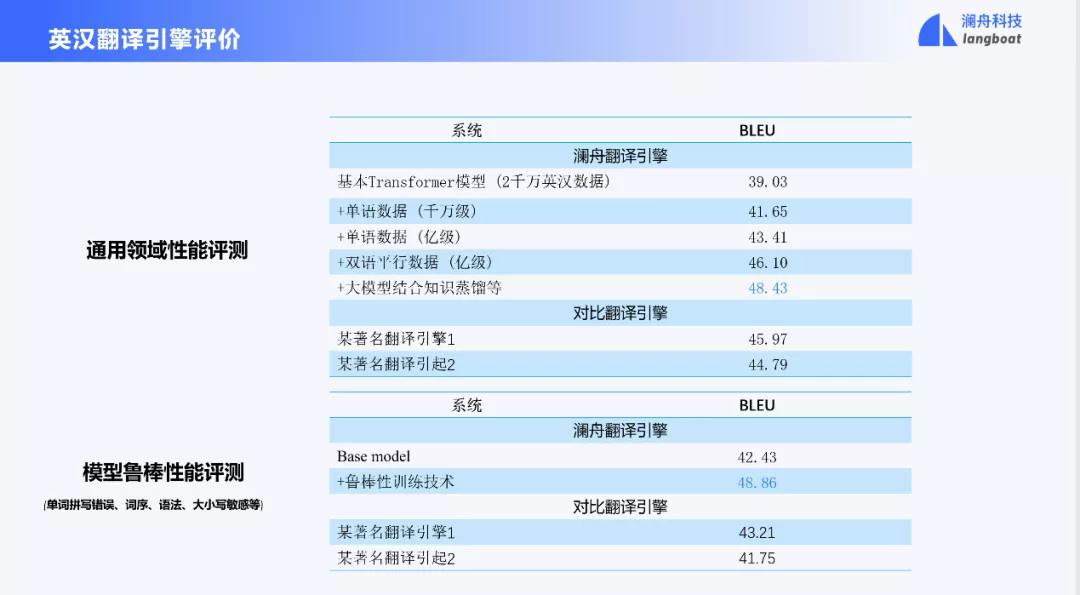
我们对比了不同训练数据和策略下的模型性能,从上表可以看出,通过利用大规模双语数据和单语数据的结合,可以有效改进翻译性能。
通常在数据量比较充足的情况下,训练参数较多的神经网络模型(更宽、更深),能取得更好的性能。然而大模型推理速度较慢,不利于在线部署。对此的解决方法是,我们先训练一个大模型,然后采用知识蒸馏的方法利用大模型训练较小模型。通过训练较大模型提高性能,通过较小模型方便部署。
澜舟与传神语联网合作,建立了通用翻译和多个领域的翻译引擎,包括机械、汽车、工程、法律、石油、合同、电力等众多领域,达到了世界领先水平。
文本生成#
自然语言处理的核心任务是语言理解和生成,现阶段,自然语言理解技术已经相对比较成熟,比如文本分类、实体识别等技术。随着技术的进步和时代的发展,自然语言生成开始崭露头角,受到越来越多的关注,特别是以 GPT 为代表的预训练语言模型的提出,使自然语言生成的大规模落地成为了可能,聊天机器人、智能问答、新闻撰写、营销文案生成等产品开始走向工业化应用。
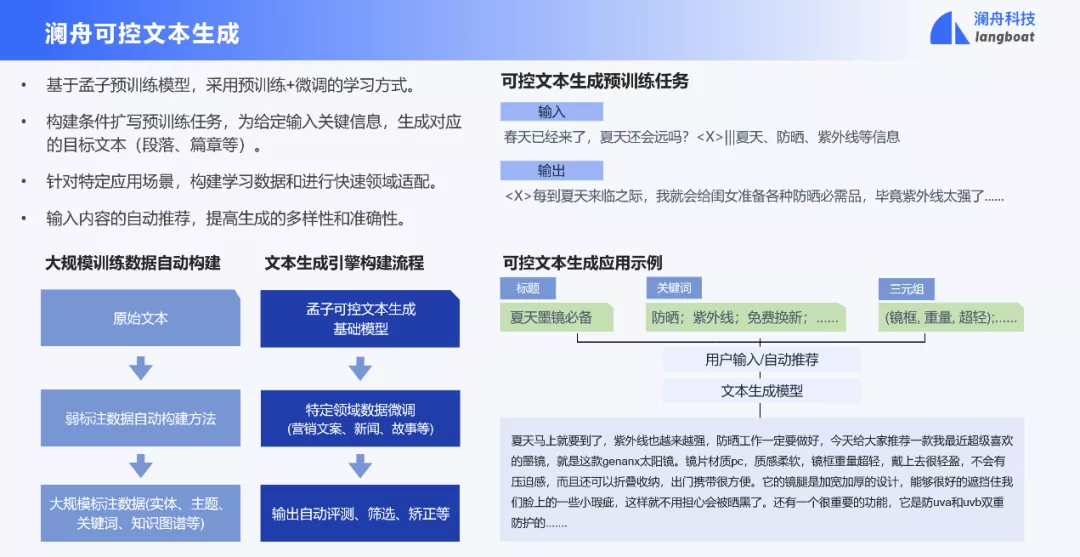
在自然语言生成中,一个很重要的研究方向是可控文本生成。可控文本生成任务是指给定关键信息,如主题、情感等内容,模型能根据这些信息生成符合要求的文本。可控文本生成有很多应用场景,如诗歌生成、文案生成、故事生成等。
澜舟针对可控文本生成做了很多工作,在孟子预训练语言模型的基础上,开发了孟子可控文本生成模型,基于条件扩写任务训练模型。具体的,我们从原始文本中抽取出实体、关键词、主题词、三元组等信息作为输入,然后生成对应的目标文本。针对应用场景,我们构建了内容自动推荐引擎,如果用户只输入个别关键信息,我们通过联想功能从对应知识库中找到相关联的信息作为输入推荐给用户,比如用户输入洗发水,可以联想到洗发水的功能,去屑、柔顺、防脱发等。
在自然语言生成中,除了文本的自动生成之外,还有一个十分重要的就是对机器生成的文本进行评测。对此,澜舟建立了比较完备的文本生成自动评测体系,从内容可控性、前后一致性、表达精炼度、文本流畅度等方面评测机器生成文本的质量。
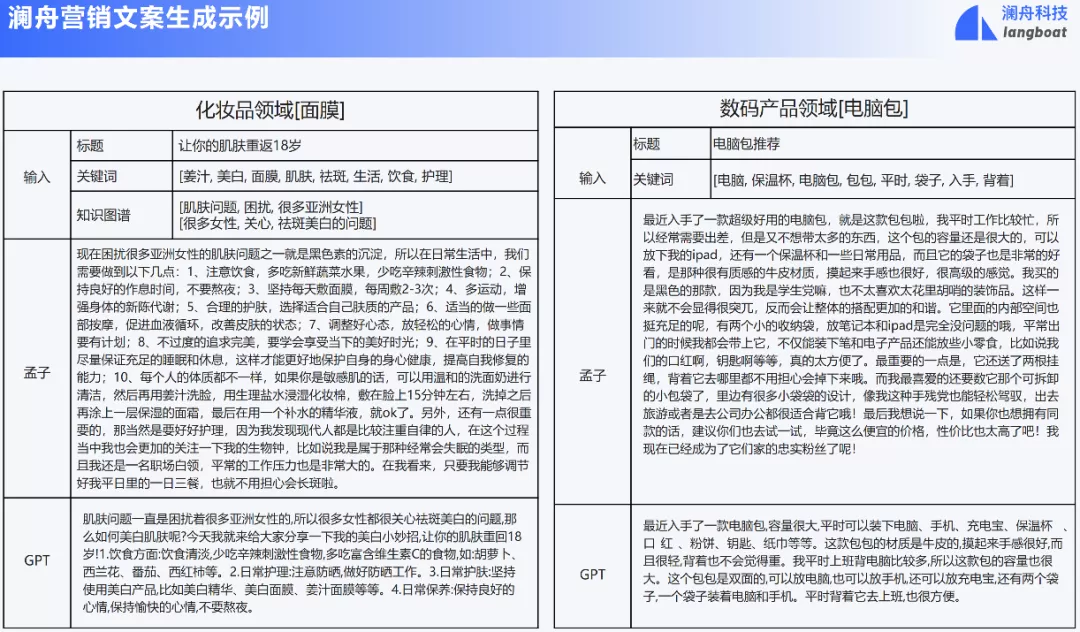
以营销文案生成为例(与数说故事合作)。如上所示,一个是化妆品领域的营销文案,另一个是数码产品领域的营销文案。我们对比了孟子可控文本生成模型和 GPT 生成的结果,可以看到孟子模型在生成内容上更加丰富,由此也证明了通过可控预训练等任务,我们可以建立更好的文本生成模型。
搜索引擎#
近几年预训练模型的发展,尤其是 BERT 模型提出至今的三年,基于预训练模型的搜索引擎新范式得以确立。新的搜索引擎范式和传统搜索引擎相比有三点重要变化:
- 模型算法基于预训练
- 搜索对象向量表示
- 神经网络学习代替人工特征工程
这些变化将推动搜索引擎技术的通用性和搜索能力的进步。澜舟搜索引擎在开发之初就坚持打造新型搜索引擎范式,澜舟科技在 NLP 和预训练模型的领先技术也为澜舟搜索引擎提供了强有力的支持。
不失一般性的,搜索引擎的流程如图1所示。
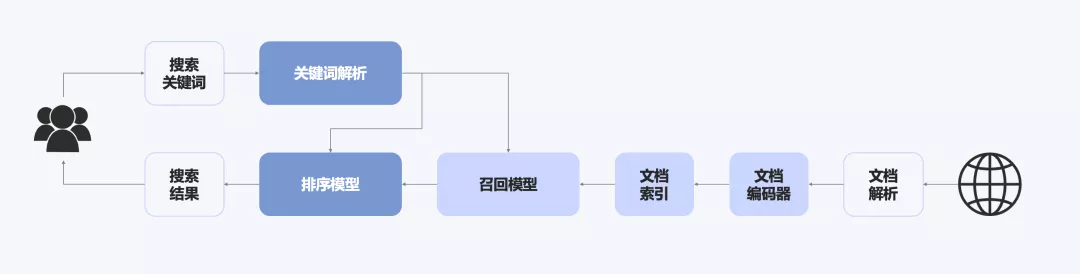
预训练模型在搜索的核心阶段起到重要作用:
- 索引:基于预训练模型增加文档的表示,生成索引
- 召回:基于预训练模型分别生成搜索关键词和文档的表示,计算相关性
- 排序:基于预训练模型对合并的搜索关键词和文档,计算相关性
此外,信息和知识抽取技术也是搜索引擎的中一个重要模块。澜舟搜索引擎,在召回、排序、信息和知识抽取领域的工作一直紧跟技术的前沿,并且始终关注在行业落地的通用性和效果。孟子金融预训练模型成为我们在金融搜索领域取得领先技术的重要支撑。
澜舟金融搜索引擎就是一个新型搜索范式在专业领域快速落地的尝试。澜舟搜索引擎结合孟子的金融预训练模型,我们快速开发了一个在金融领域有较好效果的搜索引擎原型:澜舟搜索 Beta。澜舟搜索 Beta 主要包含两部分功能:基本金融信息搜索功能和投研辅助搜索功能。
基本金融信息搜索功能包括:公司股价和基本信息、新闻、公告、研报。还包括投研辅助功能,包括脱水研报、产业链和事件链搜索。
脱水研报:
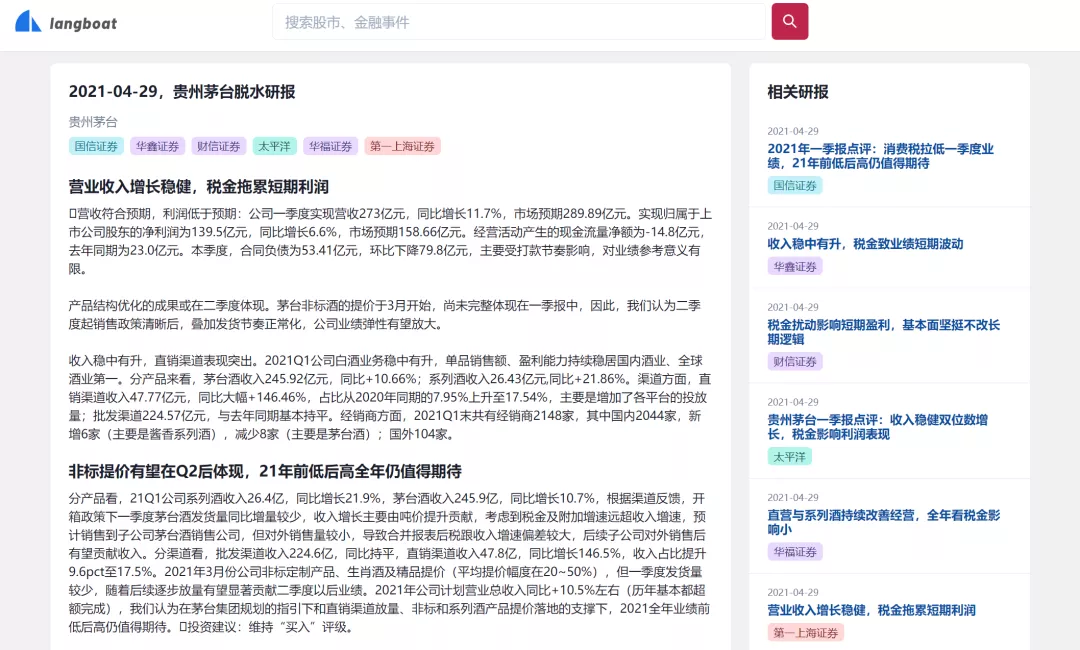
用户在阅读公司研报的时候,经常要在好多篇研报中筛选。而每篇研报通常都包含十几页甚至几十页不等的大量信息,阅读、筛选需要花费不少时间。澜舟的脱水研报基于多文档文摘和阅读理解技术。通过讲用户搜索到的研报,进行段落的解析和脱水过程,得到一份精简的覆盖几篇研报主要信息的“脱水”研报。用户通过阅读脱水研报,可以更快速的确定那些研报中有关系的信息,然后再选择精度相关研报。
产业链和事件引导的搜索体验:
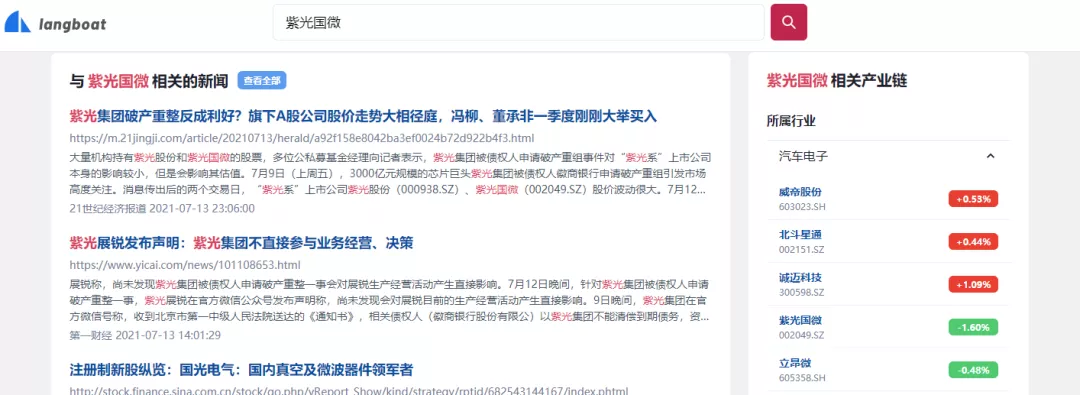

产业链和事件是金融投资的重要信息。在搜索一家公司信息的过程中,结合产业链和相关事件的信息,用户会产生新的搜素需求,进而更全面和深入的了解一家公司。用户搜索词经过产业链图谱、信息索引和事件索引得到公司相关的产业链、新闻、研报、公告和事件。通过将所有信息整合,用户可以在产业链和相关事件中找到新的信息点,从而引导用户进一步获取信息。
总结#
以 NLP 为核心的认知智能正处在蓬勃发展的势头。进一步推动了产业智能化革命。在本讲座中,我们介绍了孟子轻量化预训练模型、新一代的机器翻译、文本生成和搜索技术。但是我们也要清醒地看到预训练也遇到了不可解释、不绿色环保、数据偏差等问题。今后的发展方向,一个是沿着预训练的延长线,增强模型蒸馏、压缩、轻量化模型的核心技术,减轻数据偏差和隐私带来的问题。并且在产业中找到更多的应用。另外,还需要在许多算法方面解决一些重要问题。包括神经网络系统和知识系统的融合,研究更好的小样本学习机理,常识的激活和建立,可解释机制等。




