Langboat Cognitive Intelligence Platform
Langboat Cognitive Intelligence Platform is an industry knowledge service cloud platform with NLP as the core. It provides a series of services such as search, generation, translation, and dialogue.
Enterprise Applications

Langboat Smart Knowledge Base
An enterprise intelligent knowledge base platform in the era of large models.

Langboat Smart Agent Builder
Enterprise Intelligent Agent Application Development Tool Platform

Langboat Meeting Assistant Platform
Deep analysis of meeting audio and video, quickly capturing key information.

Langboat Intelligent Translation
Langboat's intelligent translation matrix, leading in effectiveness, with flexible and diverse usage.

Mengzi Models
A powerful self-developed generative controllable large language model.



Welcome to Langboat Mengzi Community!
Langboat Technology provides learning guidance for developers who want to get started with NLP technology
 Scan code to join Mengzi open source community
Scan code to join Mengzi open source communityIntroductory NLP Fundamentals Course
NLP Advanced Course
Paper Lead Reading | Stop the Fourth Paradigm: See how new hot search enhancements do text generation!
At the end of 2021, DeepMind released the retrieval-based language model Retro (click the green word to view previous pushes), which aroused widespread interest. Obviously, the NLP Community has found a new front (rè) along (diǎn) direction after Prompt, contrastive learning, etc.
Retrieval-enhanced text generationhas two main features:
- Non-parametric approaches: knowledge is explicitly acquired from outside the model in a plug-and-play manner, rather than being stored in model parameters.
- Simplify the text generation problem: Compared with text generation from scratch, some guidance on the retrieval results can reduce the difficulty of text generation.
It is still the old saying: "Knowledge has no limit, but the model has no limit, and if there is a limit, it will follow the limitless!" It is an inevitable trend in the development of NLP to combine lightweight models with retrieval to create an Open System!
Paper title
A Survey on Retrieval-Augmented Text Generation
Author institution
Huayang Li,Yixuan Su,Deng Cai,Yan Wang,Lemao Liu
Thesis unit
Nara Institute of Science and Technology, University of Cambridge, The Chinese University of Hong Kong, Tencent AI Lab
Paper link
https://arxiv.org/abs/2202.01110
Retrieval-Augmented Paradigm#
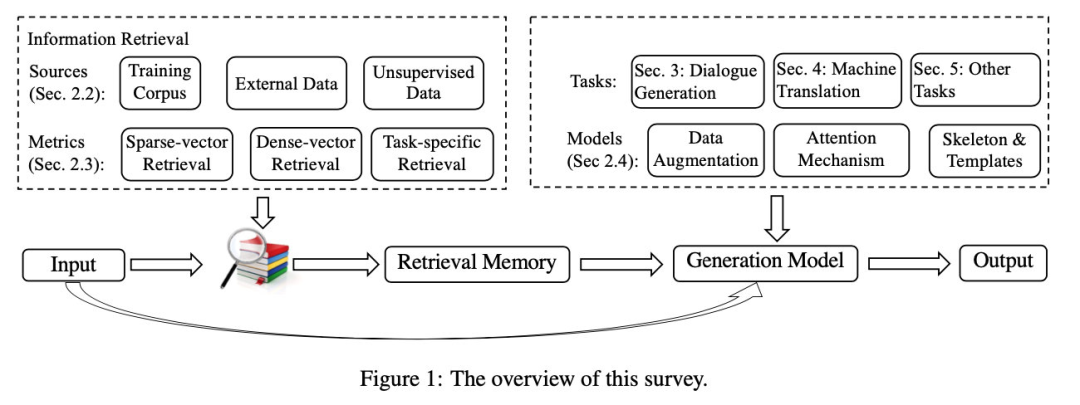
Formalized:
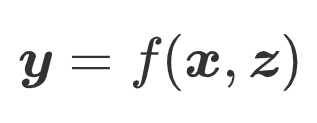
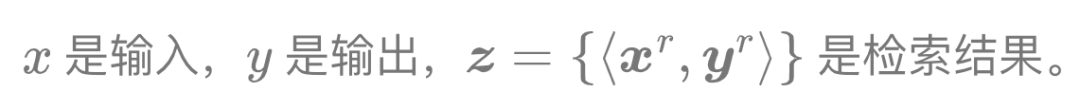
Retrieval Sources#
- Training set: the model can reuse the training set data in the inference stage
- External data set: some information is added on the basis of the training set, which is very suitable for domain adaptation or knowledge update
- Unsupervised data: the first two are supervised data, this source is the case of
Retrieval Metrics#
-
sparse-vector retrieval: such as TF-IDF, BM25, etc., mainly for relevance matching.
-
dense-vector retrieval: dual/cross-encoder, etc., mainly semantic matching.
-
task-specific retrieval: The first two methods are independent of end-task, but in fact, it is not enough to judge the reference value of only by the similarity between and , so you can consider unifying retrieval and end-task , train a task-dependent retriever.
Integration#
With the retrieval results, how can they be used to enhance the language model?
- Data augmentation: concatenating spans from with the original input
- Attention mechanism: Use an additional encoder to encode the retrieval results and fuse them together through attention
- skeleton extraction : Extract skeletons from the retrieval results, and then fuse these skeletons during the generation process
`Skeleton : A sentence template that can express the general meaning (a part of a whole utterance with irrelevant content masked )
Application#1: Dialogue Response Generation#
There are two types of dialogue systems: chit-chat and task-oriented. Here we focus on chit-chat:
Generally speaking, there are two technical routes for dialogue:
- Retrieval-based : Retrieve conversations in the realworld and return simple processing results
- Generation-based : Text generation based on dialogue history
-
Shallow Integration: Integrate retrieved instances and dialogue history through encoder, etc.
-
Deep Integration: Generally speaking, the skeleton is first extracted from the retrieval results, and then the skeleton is used to enhance the output response.
-
Knowledge-Enhanced Generation: It is not necessary to only retrieve conversations. This method uses external knowledge (such as knowledge bases, knowledge graphs, etc.) for generation enhancement (Knowledge-grounded dialogue response generation).
The current retrieval-enhanced dialogue system has the following Limitations:
- Only consider one retrieved response. How to expand to multiple?
- Can some custom retrieval metric be used? Especially for the task of controllable dialogue generation.
- Can the retrieval pool be extended from dialogue corpus to multi-domain, multi-modal, etc. corpora?
Application#2:Machine Translation#
Retrieval-enhanced machine translation generally refers to technologies related to translation memory (TM).
Statistical Machine Translation#
SMT mainly consists of three parts: phrase table extraction, parameter tuning and decoding. Translation memory (TM) can play a role in each part.
- constrained decoding: first use the edit distance to identify the unmatched segments in and , which are recorded as and respectively, and then find the correspondence of through the word alignment algorithm aligned unmatched segments in , and finally use the decoding result of to replace the corresponding
- phrase table aggregation: extract translation rules from the retrieval results, enhance the phrase table, and then readjust the parameters of the SMT model
- parameter tuning: When translating a sentence, first retrieve some similar pairs, and use these retrieval results together with the given development set to readjust the model parameters. That is, for each input, the model parameters are tuned independently. There are still some limitations to the current search-enhanced SMT:
- Retrieval only considers relevant similarity (relevance matching), and the ability of semantic matching (semantic matching) is weak
- The knowledge embedded in the search results is underutilized
- Because SMT is a pipeline, the joint optimization of retrieval metric and SMT model cannot be performed (that is, the above task-specific retrieval method cannot be used)
Neural Machine Translation#
Only use retrieval data in Inference: In the inference process, rewards are given to some specific target words based on yryr, such as increasing the probability of specific vocabulary generation.
sentence-level : Judge the amount of reward based on the sentence-level similarity. For example, the more similar is to , the higher the sampling probability of certain words in .
token-level : Judging the size of the reward based on the similarity of the token level. For example, the more similar is to , the higher the sampling probability of .
The retrieved data is ready to use during the training phase:
-
Data augmentation
-
Integrate into the model using gating, attention, encoders, etc. The current retrieval-enhanced NMT also has some limitations:
-
How to better determine reward scores?
-
How to judge when to use retrieved data and when not to use it?
Other Tasks#
Language Model#
-
KNN-LM [1] : Take the input hidden representation as the query, find k nearest neighbor samples from the training set, and use the targets of these k samples to change the result of direct inference through interpolation.
-
REALM [2] : Both pre-training and fine-tuning stages have retrieval enhancements. Divided into Knowledge-Retriever and Knowledge-Augmented Encoder. The former is responsible for enhancing instances based on input retrieval, and the latter is responsible for predicting output based on input and retrieval results (generally use special symbols to splice the two together before and after the encoder)
-
RAG [3] : REALM is based on MLM, and RAG is based on BART. A new Generator is added, which extends the range of tasks that the retrieval enhanced language model can do to the generation task.
-
RETRO [4] : DeepMind's Retrieval Enhanced Language Model, please see Langboat Technology's previous papers with reading~
Summary, restatement, style transfer, etc.#
It can be to retrieve some similar sentences for enhancement, or to retrieve some exemplar (such as syntax template, etc.).
Data-to-Text#
Retrieve some candidates from massive unlabeled corpus through input, then extract some fine-grained prototypes based on similarity, and then perform conditional text generation.
Future direction#
-
Retrieval Sensitivity: A bottleneck in retrieval enhanced text generation is that it is highly dependent on the similarity between query and retrieved instances. Generally speaking, the larger the retrieval pool is, the easier it is to find more similar samples, and the problem will be alleviated.
-
Retrieval Efficeincy:Because of the new retrieval step, inference will become slower. Therefore, it is necessary to reduce the size of the retrieval pool and find a balance between sensitivity and efficiency.
-
Local vs. Global Optimization:For the retrieval metric of the generation task, there is a gap between training and inference. Only a part of the retrieved data is used for local optimization during training, and a global search is required for the retrieval pool during the inference phase. Therefore, it is necessary to research better retrieval metric.
-
Multimodal
-
Diverse & Controllable Retrieval
Write at the end#
Now let's recall Prompt: When it comes to text generation, we say that Prompt mainly benefits in four scenarios: low resources, low computing power, unified scenarios, and controllability. To sum it up, learn the ability to use the internal memory of the model through low-energy consumption, rather than forcibly transforming the model memory from "generalist" to "specialist" through high-energy consumption.
Now that retrieval enhancement has entered the field of vision of the community, we have new thinking about large models (or LMaaS, see [6]): If Prompt is essentially a query of model memory (implicitly retrieve knowledge from model parameters ), the essence of retrieval enhancement is a query of world data (explicitly retrieve knowledge from the open outside world), then, can’t it further simulate the human language generation process:
Generally speaking, the human brain is very energy-efficient. It only saves and memorizes key and commonly used information, and then learns how to recall these memories. For uncommon and uncritical information, the help of external memory units (such as books, the Internet, etc.) is generally used. The large model should also be like this: if the desired information cannot be prompted from the model memory, use retrieval-augmented instead, and then update the model memory with the retrieved results or the generated results after retrieval enhancement, and continue. When the user base is large enough and the number of calls is large enough, the model memory will gradually converge to a stable state where only common key information is saved.
"Know what you know, what you don't know is what you don't know, that's knowing!" The model knows what to do, so it prompts the results. If you don't know, just inquire and learn honestly~
Of course, the retrieved information can also be used as a kind of prompt, similar to in-context learning. It is equivalent to using external knowledge to stimulate internal memory, "Baidu, you will know"~
The pain point that can be solved in this way is: In fact, the useful information (knowledge) acquired by pretraining is very sparse, and even most of it may be useless information (this may be the reason why the pre-training model cannot be directly used for some end-tasks. ...). Through this interactive convergence process, the density of model knowledge can be guaranteed, and the utilization rate of model parameters can be improved! So: In the era of prompt-based and retrieval enhancements, we can finally change the pre-training-fine-tuning paradigm to the steady-state paradigm of LMaaS! I believe that such a large model is closer to the human brain. After all, the birth of human language does not start from text data, but from interaction (interpersonal communication). Of course, this is just a brain-hole-level idea, and it is uncertain whether the actual development direction will be like this. After all, the current search enhancement can only be said to be semi-open, because the "outside" is often limited to a certain training set, knowledge base, etc., but the fully open method (Browser-assisted, such as WebGPT [5]) plus the above picture also faces problems such as low-speed reasoning, high system integration, and slow convergence.
Finally, turn your eyes back from the sky to the ground: at the moment when large models are rampant, search enhancement is undoubtedly an "out-of-the-circle tip" that needs to be paid attention to for enterprises or laboratories with weak computing power.
References::
[1]. kNN-LM : https://openreview.net/pdf?id=HklBjCEKvH
[2]. REALM : https://arxiv.org/abs/2002.08909
[3]. RAG : https://arxiv.org/abs/2005.11401
[4]. RETRO : https://mp.weixin.qq.com/s/oJvi8GNDdHtqjlm6TMubMA
[5]. WebGPT : https://arxiv.org/abs/2112.09332
[6]. Black-Box Tuning for Language-Model-as-a-Service: https://arxiv.org/abs/2201.03514
Products
Business Cooperation Email
Address
Floor 16, Fangzheng International Building, No. 52 Beisihuan West Road, Haidian District, Beijing, China.
© 2023, Langboat Co., Limited. All rights reserved.
Large Model Registration Code:Beijing-MengZiGPT-20231205
Business Cooperation:
bd@langboat.com
Address:
Floor 16, Fangzheng International Building, No. 52 Beisihuan West Road, Haidian District, Beijing, China.
Official Accounts:

© 2023, Langboat Co., Limited. All rights reserved.
Large Model Registration Code:Beijing-MengZiGPT-20231205


