Langboat Cognitive Intelligence Platform
Langboat Cognitive Intelligence Platform is an industry knowledge service cloud platform with NLP as the core. It provides a series of services such as search, generation, translation, and dialogue.
Enterprise Applications

Langboat Smart Knowledge Base
An enterprise intelligent knowledge base platform in the era of large models.

Langboat Smart Agent Builder
Enterprise Intelligent Agent Application Development Tool Platform

Langboat Meeting Assistant Platform
Deep analysis of meeting audio and video, quickly capturing key information.

Langboat Intelligent Translation
Langboat's intelligent translation matrix, leading in effectiveness, with flexible and diverse usage.

Mengzi Models
A powerful self-developed generative controllable large language model.



Welcome to Langboat Mengzi Community!
Langboat Technology provides learning guidance for developers who want to get started with NLP technology
 Scan code to join Mengzi open source community
Scan code to join Mengzi open source communityIntroductory NLP Fundamentals Course
NLP Advanced Course
Graphic Record|UIE: Universal Information Extraction Based on Unified Structure
Background#
The purpose of information extraction is to extract knowledge from various information sources and integrate it into the existing structured knowledge base. Usually, the knowledge categories we extract include three types: entities, relationships, and events. Entities include names of people, places, institutions, etc.; relationships include CEO relationships, parent-child relationships, part-whole relationships, etc.; events are usually related to events we care about, such as presidential elections, conferences, and terrorist attacks.
Difficulties in information extraction#
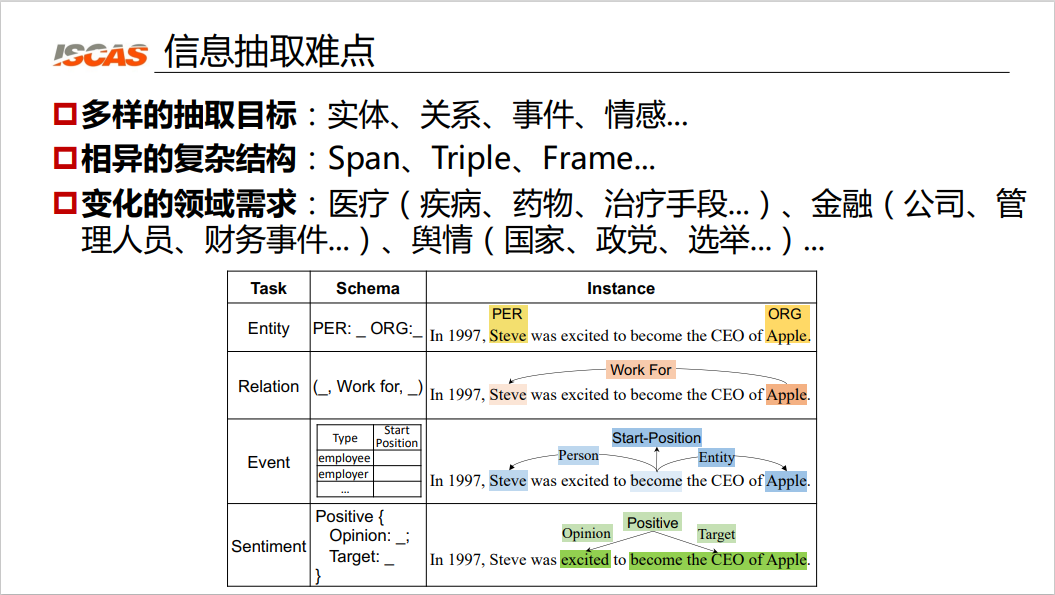 Figure 1: Difficulties in information extraction
Figure 1: Difficulties in information extraction
Difficulties in information extraction include diverse extraction targets, different complex structures, and changing domain requirements.
First, unlike traditional NLP tasks, the goals of information extraction are very diverse. We may need to extract entities, relationships, events, emotions, etc. Second, the target of information extraction has a complex structure, as shown in the table at the bottom of Figure 1, the entity in the first row is a Span structure, that is, a string structure, and the relationship is a triple structure. In the second example, the relationship is a Work-For relationship, which expresses the Work-For relationship between Steven Jobs and Apple. The third example is a complex frame structure. The third difficulty is its changing domain requirements. For example, if knowledge in the medical field is to be extracted, the objects usually extracted are diseases, drugs, treatments, etc. If you want to make related applications in the financial field, the objects to be extracted are companies, managers, financial events, etc. If you want to make applications related to public opinion, the objects to be extracted will be different, and you need to extract countries, political parties, elections, etc.
Status of Information Extraction#
First, depending on the task, there will be a task-specific architecture. For example, if you do named entity recognition, you would use a sequence annotation model. If you do relationship extraction, you will use models such as relationship classification. This leads to the need for professionals to tune the information extraction model, and choose sequence annotation models, span classification models, or reading comprehension models according to the situation.
Second, due to the independence of information extraction tasks, we will train a lot of independent models. The information extraction models for different tasks are trained individually and are not shared with each other. The final result is that a company may need to manage hundreds or thousands of models for information extraction.
Finally, information extraction requires extremely high construction costs. As mentioned above, to meet the needs of different fields, different information extraction models need to be trained, and experts are required to design specific schemas and build training resources, such as labeling corpus and collecting dictionaries.
In general, a variety of extraction tasks, a variety of supervisory signals, a variety of model architectures and a variety of different knowledge areas lead to the current status of information extraction: information extraction is a complex architecture , has an explosion model, and the cost is also extremely high.
Information extraction research target: Universal IE#
In response to the above problems, we hope to build a general information extraction model. Therefore, we have the following three research objectives:
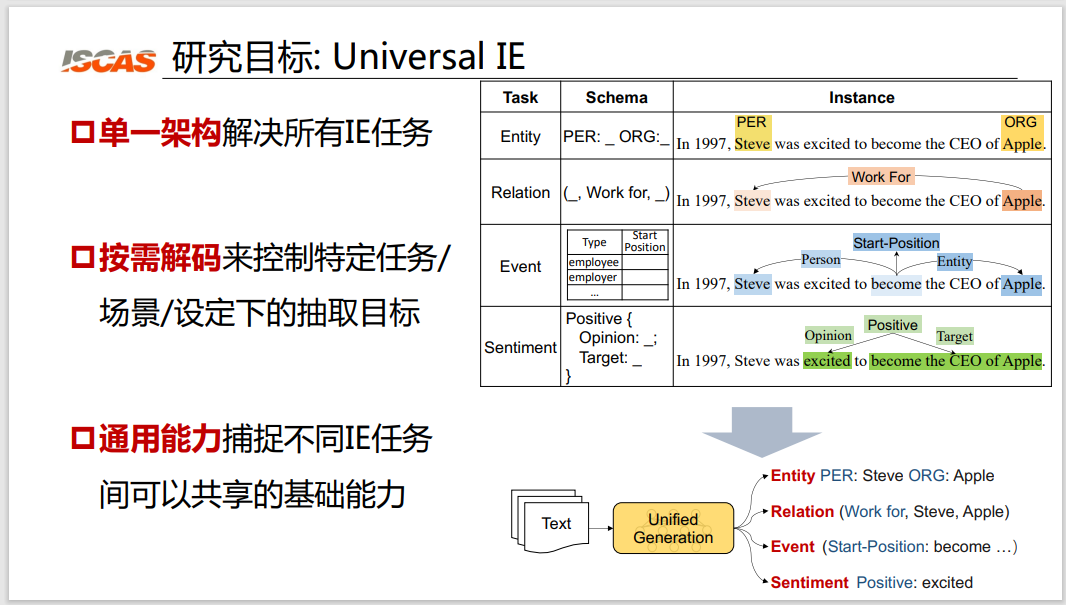 Figure 2: Three research objectives
Figure 2: Three research objectives
First, we hope to be able to use a single architecture to solve a wide variety of information extraction tasks. As shown in the table on the right side of Figure 2, we hope that all tasks of complex entity extraction, relationship extraction, event extraction and emotion recognition can be solved using a unified architecture.
Second, we hope to have an on-demand decoding mechanism to control specific tasks, scenarios, and set extraction goals. For example, we hope to have a mechanism to tell the model that when doing medical treatment, we only need to extract knowledge in the medical field; when doing emotion, we only need to extract knowledge related to emotion.
Third, we hope to have a general ability to capture the basic capabilities that can be shared between different extraction tasks. For example, we hope that all named entity recognition models can share the ability of named entity recognition, and all relation extraction and event extraction can share the ability of structure extraction.
Information extraction research work: Universal IE#
For the three goals mentioned above, we also have three corresponding research works:
First, for the goal of a single architecture, we propose a text-to-structure (Text-to-Structure) generation architecture; for on-demand decoding, we propose a constraint decoding mechanism based on the Prompt structure; in response to the general capability requirements, we propose a large model for pre-training information extraction.
Next, we will introduce our research work in three aspects:
A Single Architecture: Text2Structure Unified Generative Architecture As mentioned earlier, information extraction has a wide variety of tasks, so the aim of our work in this aspect is to unify various task-specific architectures into a single task-generic architecture. We found that different IE tasks can be defined as text-to-structure generation tasks.
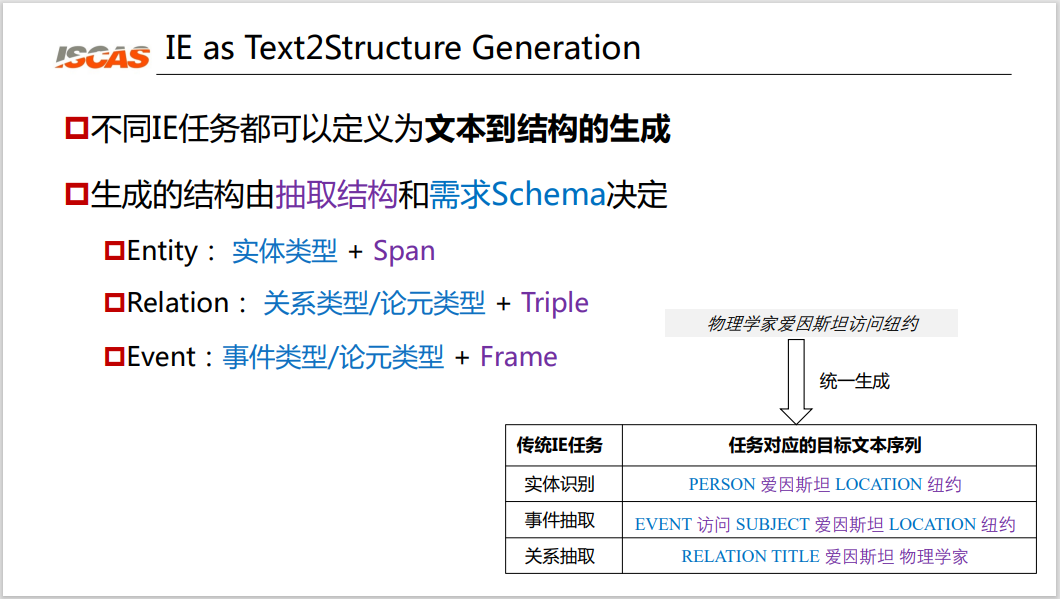 Figure 3: Single architecture
Figure 3: Single architecture
As shown in the lower right corner of Figure 3, for a task like "Physicist Einstein visited New York", for a traditional entity recognition task, the structure would be "[Person] Einstein [Place] New York". For the event extraction task, its structure is “[Event] visit [Subject] Einstein [Location] New York”. The relationship extraction is "[Relationship Name] Einstein Physicist". We can find that all IE tasks are essentially text-to-structure generation. The generated structure is determined by the extraction structure and the requirement schema: the structure of an entity is the entity type + Span; the relationship is the relationship type/argument type + Triple; the event is the structure of the event type/argument type + Frame.
Based on such observations, we argue that all information extraction tasks can be uniformly modeled using sequence-to-structure generative networks. For example, inputting a sentence can generate the structure we want to extract. The core difficulty of this process is that our extraction goals are different. For named entity recognition, its target structure is a text block structure. The structure of the event is a multi-record structure. For example, the resignation event is composed of the trigger word "leave", the person and the source of employment, and the entry is composed of the trigger word "join", the task and the new employment location. There are also cluster-based cluster structures. For example, for the resignation event, there may be multiple sentences representing the same event. Finally, there may be nested structures. For example, in the sentence "Argentina national team captain Messi", "Argentina" is nested in the "Argentina national team captain" position entity.
To address this challenge, our main contribution is to propose a fundamental capability-inspired Structured Extraction Language (SEL) for information extraction. Specifically, we found that all the basic capabilities of information extraction include the following two: Ability to locate information points: discover information points in text, such as entities, event trigger words, etc. Ability to associate information points: establish connections between information points, such as relational arguments, event arguments, etc.
 Figure 4: Example of structured language for information extraction
Figure 4: Example of structured language for information extraction
Based on such findings, we propose a structured extraction language for information extraction that expresses these two capabilities in a unified structure. As shown at the bottom of Figure 4, an example of a structured extraction language is given for the sentence "Steve Jobs became Apple's CEO in 1997".
It can be seen that we will locate the information point in the extraction source and express it as a form of span, such as Jobs. We use "[person: Jobs]" to represent it here; express the relationship as a tuple structure, such as "[People: Jobs (Worked for: Apple)]". Through this unified structured representation language, we can convert all information extraction targets into a token sequence.
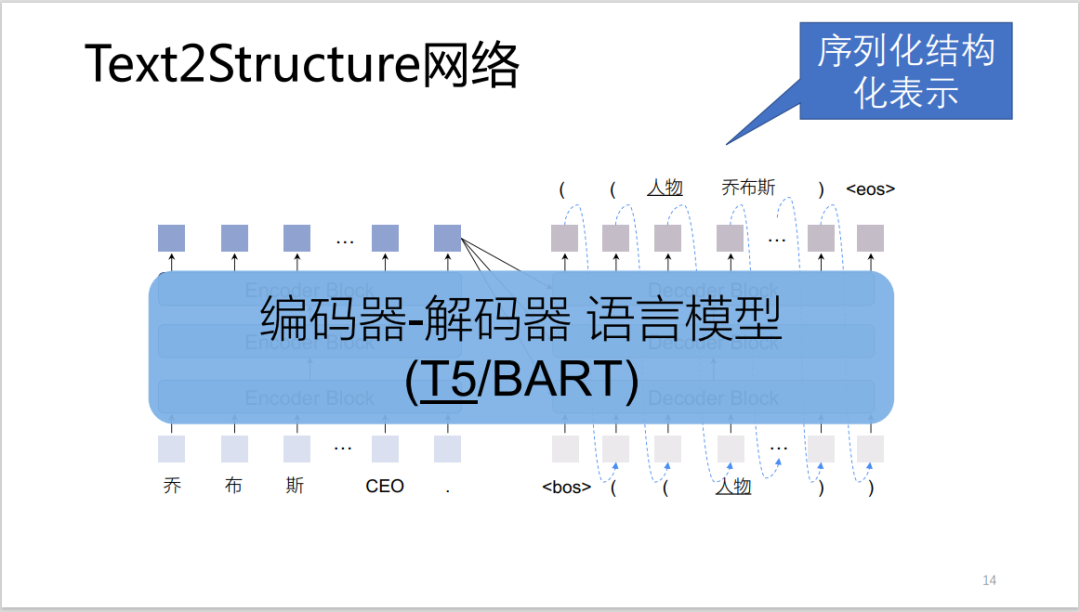 Figure 5: Schematic diagram of Text2Structure architecture
Figure 5: Schematic diagram of Text2Structure architecture
Figure 5 shows the overall architecture of the Text2Structure network.
As mentioned earlier, the second difficulty in information extraction is how to tell Text2Structure what information we want to extract (requirement schema) and how to constrain the text-to-structure model so that it can generate the correct target structure we need, and Illegal structures are not generated. In response to these two requirements, we have done two kinds of work: Aiming at the problem of how to distinguish different extraction tasks during the extraction process, we proposed a guidance mechanism based on the target information of the prompt word Prompt; Aiming at how to generate legal expressions , we propose a structurally constrained decoding mechanism.
On-Demand Decoding: Prompt-Based Structural Constraint Decoding Mechanism
First, we will introduce the target information guidance mechanism based on the prompt word Prompt. Specifically, we convert the information of the schema into a hint for the generation process, so that a hint can guide the UIE model to generate the correct information, and at the same time tell the model to locate the correct information from the original text. Then you can see the following example.
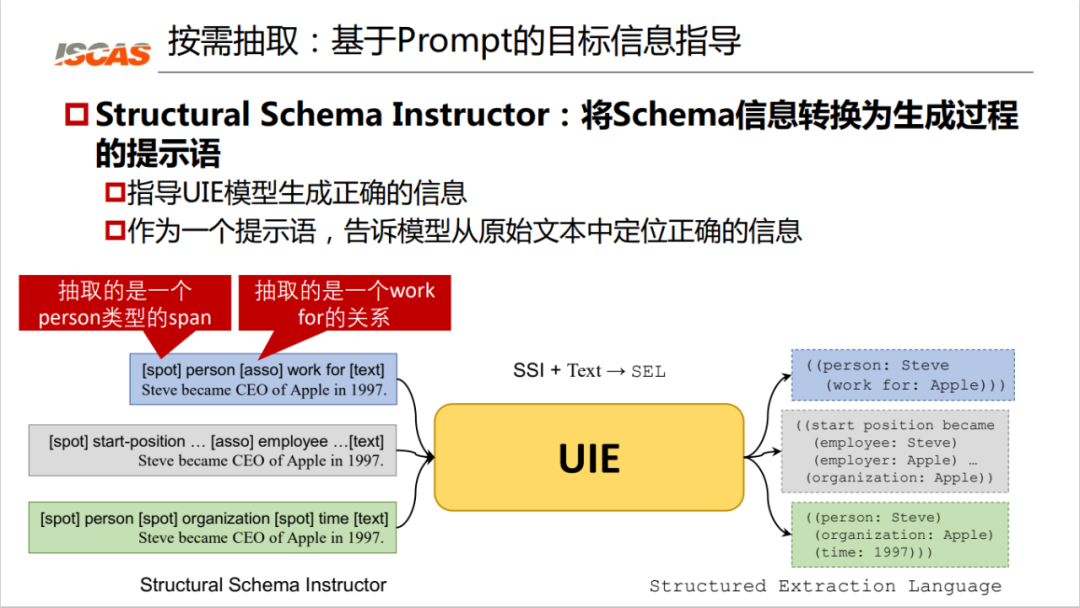 Figure 6: Converting Schema information into hints
Figure 6: Converting Schema information into hints
As shown in Figure 6, the spot prompt tells the model to locate the person entity, and asso extracts the work for relationship at the same time. It can be seen that based on such prompts, we can extract the knowledge "Jobs works for Apple" from such a sentence. If the prompt for the same sentence is "start position start-position", the knowledge it extracts is different.
Based on the prompts, we also did a second job, which is Constrained Decoding. We view the generation process as a search of a prefix tree, generate legal structure extraction expressions, and dynamically provide legal vocabulary according to the generation process. By modeling the category frame and text fragments as a generated prefix tree, the generation process is regarded as a search for the prefix tree, which constrains the decoding space and reduces the difficulty of decoding. At the same time, the constraints of the schema can also guarantee the structure and semantics. legality.
General capability: pre-training large IE models
Finally, in terms of general capabilities, we propose a pre-trained large model for information extraction. The main issues in this part of the work include how to model and learn the general basic capabilities of information extraction and large-scale pre-training for heterogeneous supervision.
Common Basic Capabilities for Modeling Information Extraction
Extraction A large number of basic capabilities are shared between different information extraction tasks. For example, noun phrase localization capabilities are shared between different named entity recognition tasks. If we can share this phrase localization ability of nouns, we can improve the performance of named entity recognition in a targeted manner. For another example, different relationship extractions share the associative ability of entities. No matter what the relationship is, it is essentially based on sentences to identify the relationship between entities. Finally, whether it is related extraction or event extraction, its basic modeling ability is essentially the ability to convert natural language sentences into a target structure.
Scale Pre-Training for Heterogeneous Supervision
We found that there are a large number of weakly supervised resources on the Internet, such as structured data DBpedia, Yago, etc.; there is also long-distance aligned data, such as Info information boxes, Wikidata, etc.; and unstructured data, such as Wikipedia, etc.
Based on these observations, by combining massive heterogeneous weakly supervised resources such as Wikipedia, Wikidata, etc., through a large-scale pre-training of general capabilities, a large model of general IE capabilities is obtained. Based on such a large model, we can design an on-demand fine-tuning and decoding mechanism for capability migration, and finally apply general-purpose capabilities efficiently to different information extraction tasks, such as entity recognition tasks, relationship extraction tasks, and event extraction. task etc.
Then, how to obtain the general basic ability of information extraction from heterogeneous supervision becomes our main concern. Finally, we have completed the work of transforming different supervisions into a unified learning task and performing large-scale pre-training tasks.
Experiment#
Specifically, we constructed three types of corpora to unify heterogeneous data into the form of <text, structure>:
 Figure 7: Creation of the pre-training corpus
Figure 7: Creation of the pre-training corpus
As shown in Figure 7, the first type is the data pair of parallel data, the left side is the text, and the right side is the knowledge extracted by it, you can see the first example in Figure 7. The input is "Steve Jobs became the CEO of Apple Apple in 1997", and the output is a triple <CEO(Steve,Apple)>. This parallel data is mainly obtained by aligning Wikidata and Wikipedia. The second type of data is structured monolingual data. We extracted all the knowledge from ConceptNet and Wikipedia. The third category is monolingual data of text, which extracts all data from English Wikipedia. We ended up constructing a total of 65 million pairs of pre-trained corpora, and uniformly modeled these corpora into a text-to-structure form. With the pre-training corpus, we designed three large-scale pre-training tasks:
Text-to-structure pre-training, where the input is text and the output is a structure. Through this pre-training, our UIE model has the ability to generate structures;
pre-training for structure generation, the input is empty, and the output is a structure. Based on such a pre-training task, we hope to use structural monolingual data to pre-train the decoder;
semantic pre-training of text, the input is text, and the output is empty. In this task we hope that the UIE model can learn information to encode the semantics of the text.
Finally, our pre-training task combines the above three tasks, which are parallel decoding task, monolingual decoding task and monolingual encoding task. Since the generation target of information extraction is structure, the generation process from text to structure is very complicated. In the pre-training process, in order to improve the stability of the learning process, we adopted a curriculum learning strategy. Specifically, let our pre-training model generate simple structures, starting from simple unary structures such as label and span to more complex structures, and finally ensure the stability of the structure generation learning process.
Experimental Results#
The UIE model was finally tested on four types of information extraction tasks, including named entity recognition, relationship extraction, event extraction, and emotion extraction tasks, as well as 12 data sets and 7 major fields.
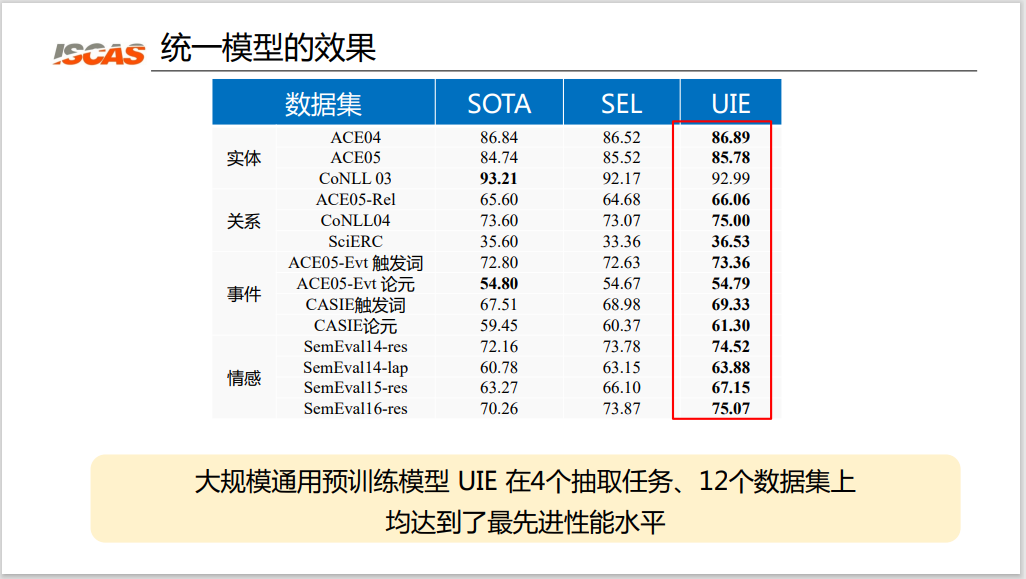 Figure 8: The effect of the unified model
Figure 8: The effect of the unified model
As shown in Figure 8, the large-scale universal pre-trained language model UIE achieves state-of-the-art performance on 4 extraction tasks and 12 datasets. It can be seen that on these four types of tasks, the results of the UIE model have achieved performance improvements compared to the current SOTA results. The second experimental result is that using the pre-trained UIE significantly improves performance compared to directly using this structured generative model SEL of T5. At the same time, for the three pre-training tasks and three pre-training corpus mentioned above, no matter which pre-training task or corpus is removed, it will lead to a certain performance reduction; adding any pre-training task can be Guaranteed performance boost. Therefore, it can be proved that the three pre-training corpora can play a certain pre-training effect.
In addition, the main purpose of pre-training large models is transfer learning, so that we can still achieve good results under low-resource conditions. We also made experimental settings for related transfer learning. Specifically, we pre-train in the original event category and fine-tune the model in the new event category. We employ a baseline model of OneIE, a text chunk classification model learned based on word-level annotations and entity annotations, and a reading comprehension model, EEQA, learned based on word-level annotations.
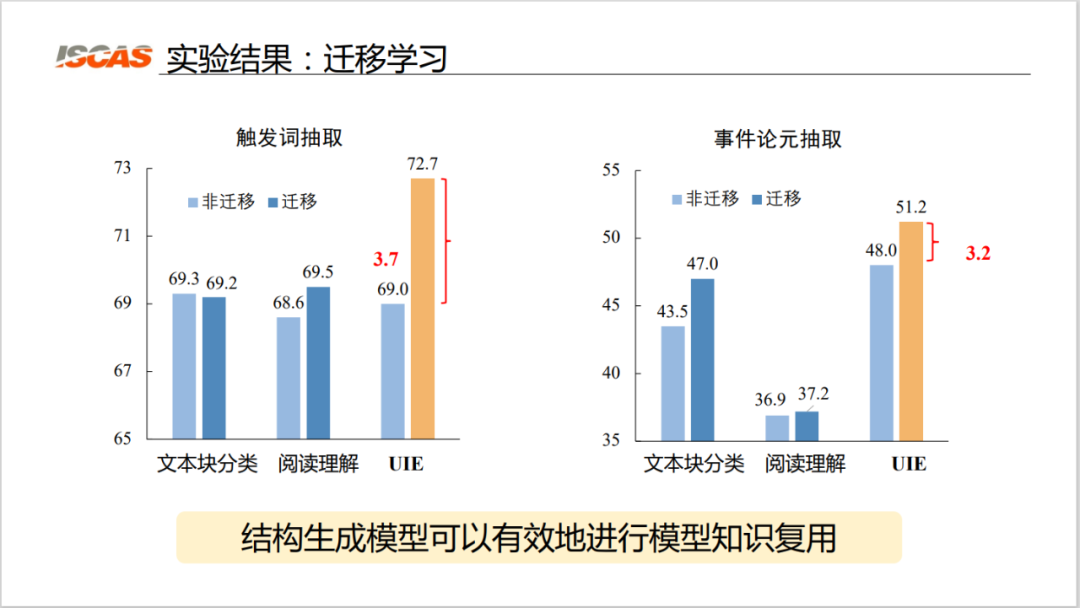 Figure 9: Transfer learning effect
Figure 9: Transfer learning effect
As shown in Figure 9, the experimental results show that the performance of the UIE-based model has been significantly improved after transfer learning. The performance of the two baseline models after migration is almost unchanged or the improvement effect is very small; after the migration of the model based on the UIE architecture, its F-value improvement is very significant, which shows that the structure generation model can effectively carry out the knowledge replication of the model. use.
Finally, we also conduct an experimental setup for small-sample general information extraction. We set some small-sample tasks and compared various baseline models, including T5-v1.1-base, Fine-tuned T5-base, etc.
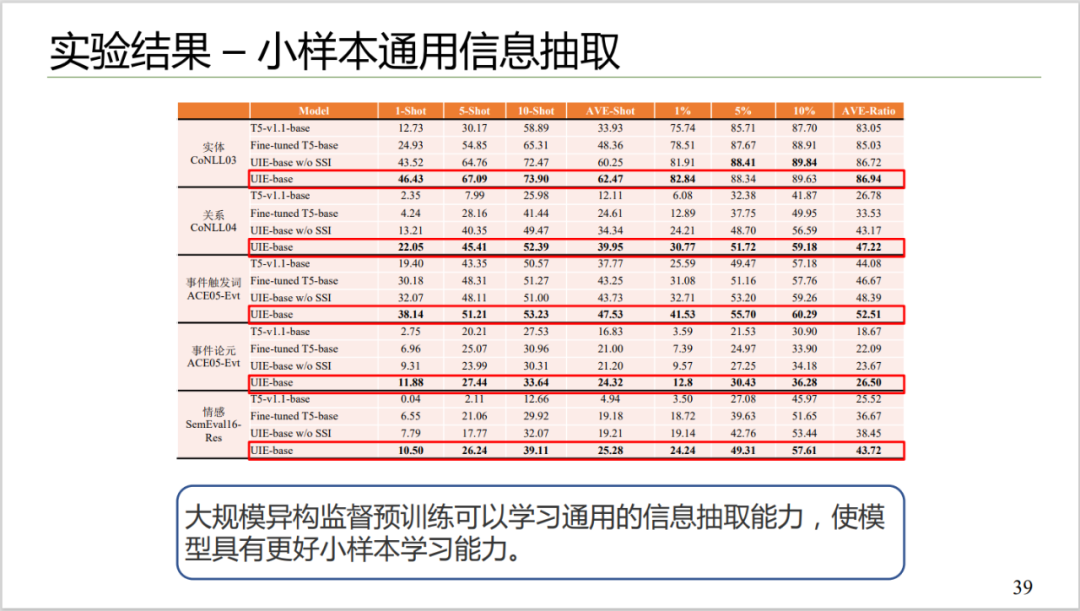 Figure 10: Small sample general information extraction effect
Figure 10: Small sample general information extraction effect
Experimental results show that large-scale heterogeneous supervised pre-training can learn general information extraction ability and make the model have better small-shot learning ability. As shown in Figure 10, the pre-trained model has a very high performance improvement. For example, on the entity task, the result on the 1-shot without pre-training is 12.73, while the result with pre-training is 46.43. At the same time, after adding the hints of structured extraction mentioned above, the learning ability of model transfer is stronger. Adding cues, for example, improves the metric from 38 to 43 on the sentiment task, compared to general information extraction without cues.
Summarize#
In general, we believe that by designing this unified text-to-structure (Text2Structure) generation architecture, plus an on-demand structure-constrained decoding algorithm based on prompts (Prompt), plus a large-scale structure based on massive corpus , the pre-training of information extraction ability can finally achieve the goal of Universal Information Extraction.
The work related to this article has been published, and the code model has also been made public. Interested readers can check the link below to read the original article. Comments and corrections are welcome.
Related Links:#
1.《Unified Structure Generation for Universal Information Extraction. ACL 2022.》:https://arxiv.org/pdf/2203.12277.pdf 2.《Text2Event: Controllable Sequence-to-Structure Generation for End-to-end Event Extraction, ACL 2021.》:https://arxiv.org/pdf/2106.09232.pdf
- Code and model: https://universal-ie.github.io/
- Chinese Information Processing Laboratory: http://www.icip.org.cn
Products
Business Cooperation Email
Address
Floor 16, Fangzheng International Building, No. 52 Beisihuan West Road, Haidian District, Beijing, China.
© 2023, Langboat Co., Limited. All rights reserved.
Large Model Registration Code:Beijing-MengZiGPT-20231205
Business Cooperation:
bd@langboat.com
Address:
Floor 16, Fangzheng International Building, No. 52 Beisihuan West Road, Haidian District, Beijing, China.
Official Accounts:

© 2023, Langboat Co., Limited. All rights reserved.
Large Model Registration Code:Beijing-MengZiGPT-20231205


