Langboat Cognitive Intelligence Platform
Langboat Cognitive Intelligence Platform is an industry knowledge service cloud platform with NLP as the core. It provides a series of services such as search, generation, translation, and dialogue.
Enterprise Applications

Langboat Smart Knowledge Base
An enterprise intelligent knowledge base platform in the era of large models.

Langboat Smart Agent Builder
Enterprise Intelligent Agent Application Development Tool Platform

Langboat Meeting Assistant Platform
Deep analysis of meeting audio and video, quickly capturing key information.

Langboat Intelligent Translation
Langboat's intelligent translation matrix, leading in effectiveness, with flexible and diverse usage.

Mengzi Models
A powerful self-developed generative controllable large language model.



Welcome to Langboat Mengzi Community!
Langboat Technology provides learning guidance for developers who want to get started with NLP technology
 Scan code to join Mengzi open source community
Scan code to join Mengzi open source communityIntroductory NLP Fundamentals Course
NLP Advanced Course
Langboat Technology Machine Translation Technology Sharing
✎ Introduction#
With the further development of the global economy, activities such as international trade, cross-border tourism and cultural exchanges are becoming more and more frequent, so the need to break down communication barriers between different languages is becoming increasingly urgent. In this regard, based on its own accumulation in machine translation technology, Langboat Technology has established a multi-language, multi-field machine translation engine, and recently released an English and Chinese financial mutual translation engine. This article is written by Dr. Liu Mingtong, a researcher of Langboat Technology, to share with you the machine translation technology of Langboat Technology.
01 Introduction to Machine Translation#
With the progress of economic globalization, translation between different languages has become an indispensable part of modern life. Broadly speaking, "translation" refers to the process of transforming one thing into another. In the translation of human language, one language is transformed into another language expression through the human brain, which is a kind of "translation" of natural language. In modern artificial intelligence systems, machine translation refers to the automatic translation of texts in one language into texts in another language by computer, such as translating Chinese into English, where Chinese is called the Source Language and English Known as the target language (Target Language). Overall, machine translation has gone through three stages: rule-based methods, statistical machine learning, and neural network machine translation. Thanks to the advancement of technology and the accumulation of corpus over the past few years, neural machine translation technology has brought significant quality improvements to modern machine translation. Machine translation has achieved very good development in the industry and has been widely used in many fields. In some Between languages, machine translation can perform as well as professional translators. Neural Machine Translation (Neural Machine Translation) refers to a machine translation method that directly uses neural networks to perform translation modeling in an end-to-end manner. Neural machine translation simplifies the intermediate steps of statistical machine translation, and uses a simple and intuitive method to complete the translation work: first use a neural network called an encoder (Encoder) to encode the source language text into a dense vector, and then use a neural network called The neural network for the decoder (Decoder) decodes the target language text from this vector. This model is usually called the "Encoder-Decoder" (Encoder-Decoder) framework. In recent years, neural machine translation frameworks represented by LSTM and Transformer have achieved significant performance improvements and have been widely used in industrial translation platforms.
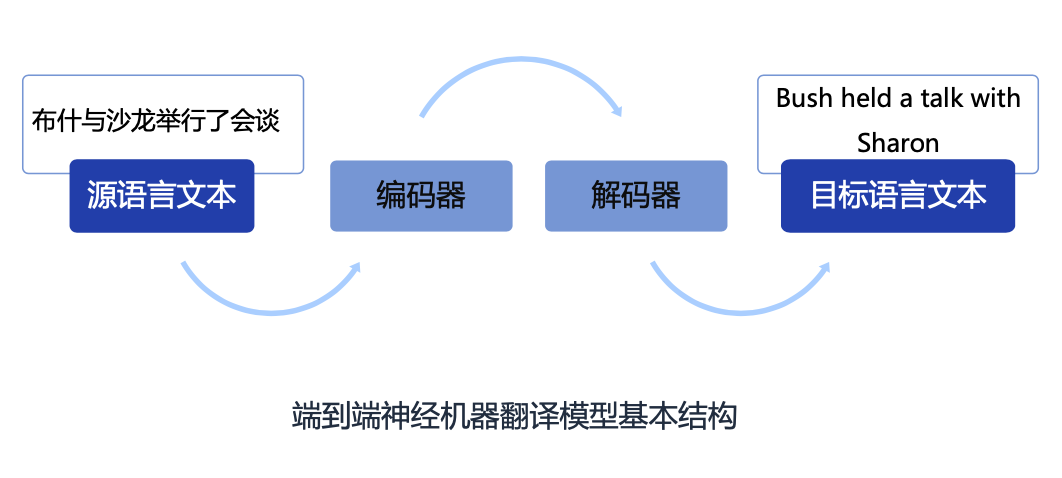
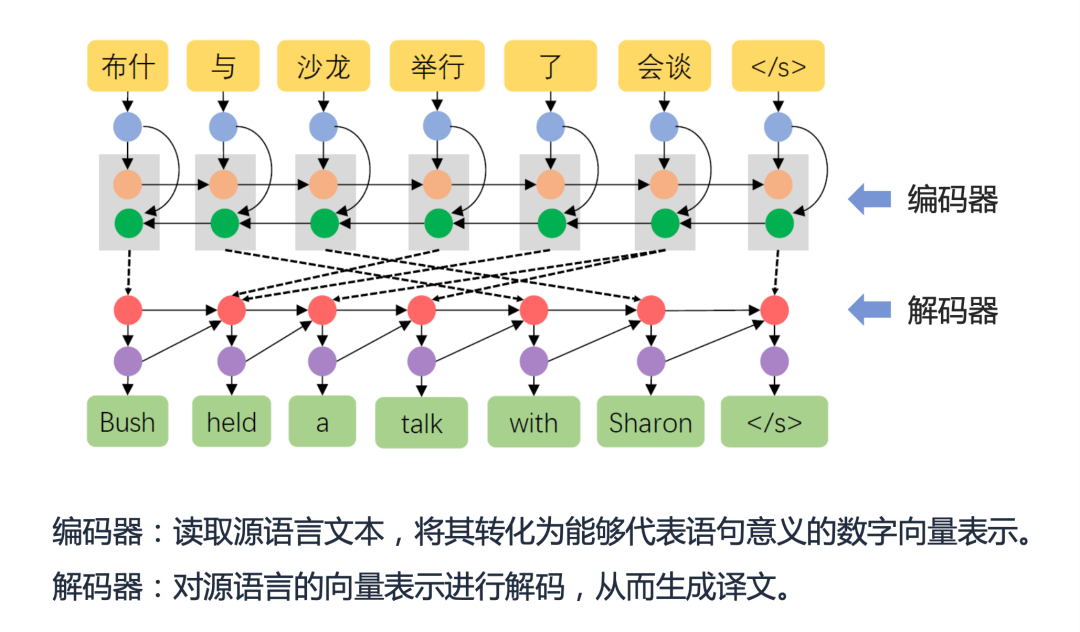
02 Neural machine translation training method#
In modern artificial intelligence systems, the core algorithm + high-quality data are the two wings of a good AI system. Building a high-quality translation model requires a large number of high-quality bilingual parallel sentence pairs. However, manually constructing such bilingual translation data is time-consuming and labor-intensive, and it is difficult to achieve in the short term. An effective method is to use monolingual data to enhance translation performance. The commonly used technique is Back-Translation. The method of using monolingual data in reverse translation technology can be summarized as follows: In order to improve the English-Chinese translation model, we first use Chinese-English parallel data to train a reverse translation model (translate Chinese into English), and then translate large-scale Chinese monolingual data For English, a pseudo-English-Chinese parallel corpus is constructed to train the English-Chinese translation model. Finally, we mixed standard translation data and generated dummy data to train the English-Chinese translation model.
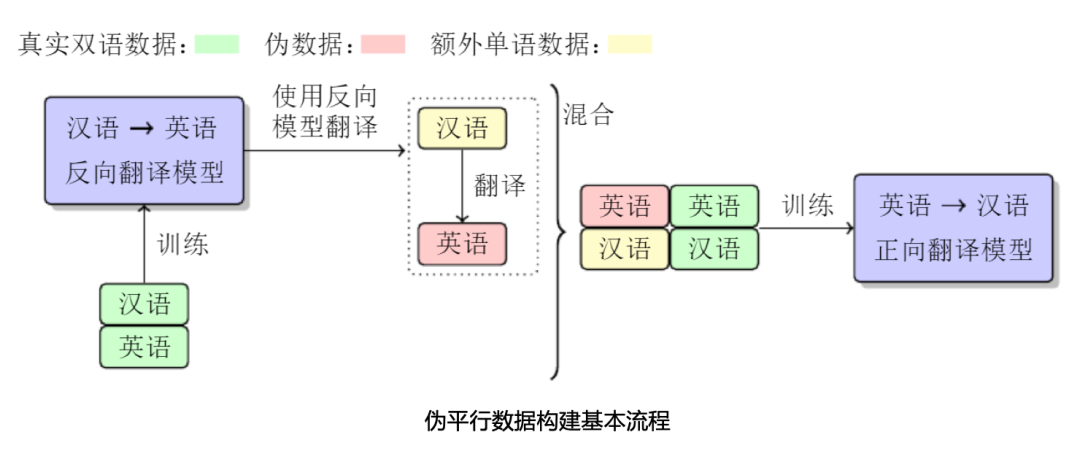
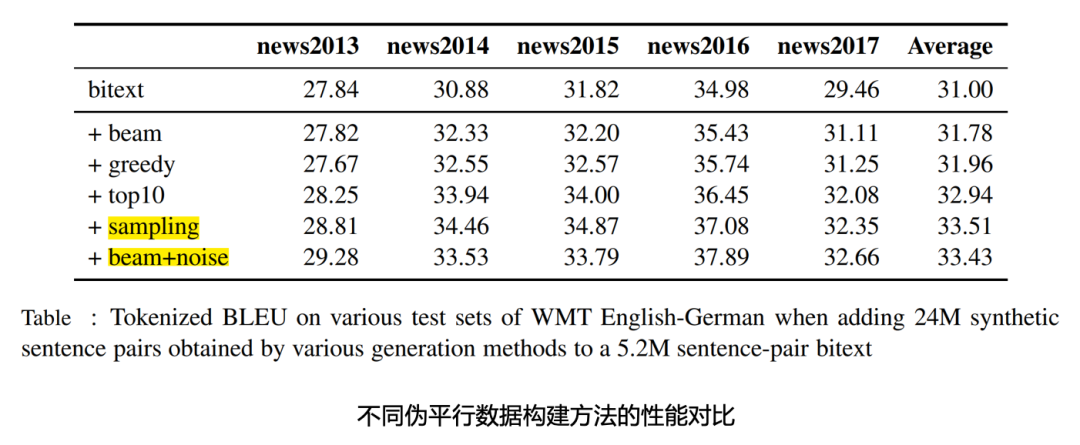
One of the difficulties in natural language processing is the diversity of language expressions. In machine translation, increasing the diversity of training data is also an effective means to improve the performance of translation models. Compared with Beam and Greedy search algorithms, using Sampling and Beam+noise methods to generate pseudo-parallel data can further improve model performance by increasing the diversity of training data.
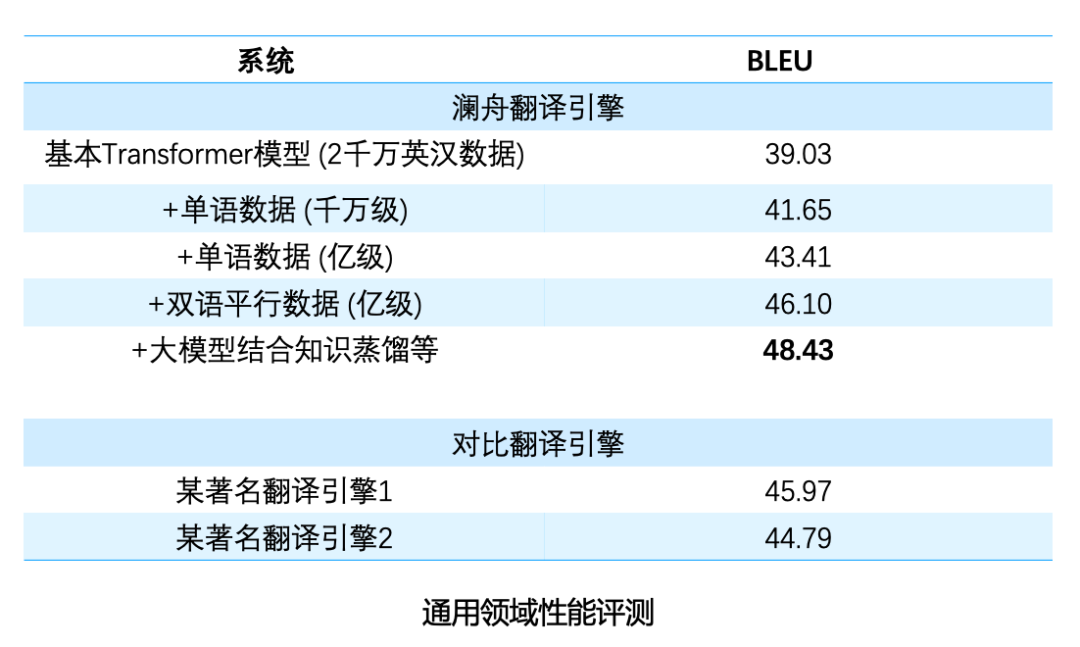
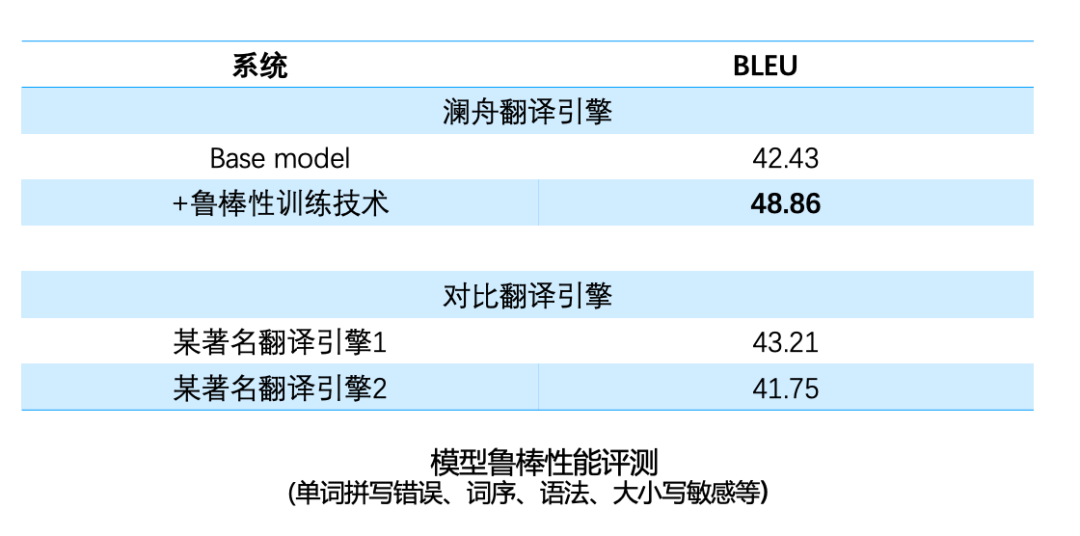
Comparing the model performance under different training data and strategies, it can be seen from the above table that the translation performance can be effectively improved by using the combination of large-scale bilingual data and monolingual data. Usually, when the amount of data is relatively sufficient, training a neural network model with more parameters (wider and deeper) can achieve better performance. However, the inference speed of large models is slow, which is not conducive to online deployment. The solution to this is that we first train a large model, and then use the large model to train a smaller model using knowledge distillation. Improve performance by training larger models and facilitate deployment with smaller models. Another key issue in machine translation is model robustness. For example, in English input, word spelling errors, word order, and incorrect grammar will occur. There are also some scenarios, such as web page addresses, Langboat has also made some targeted optimizations for mailboxes, emoticons, and some noise texts. After optimization, the robustness of the model has been significantly improved, and it can be better applied in different scenarios.
03 Method for improving machine translation performance in vertical fields#
With the improvement of translation technology and people's demand for high-quality translation engines, it is difficult for general-purpose engines to meet performance requirements, such as translation of technical terms and specific expressions in many fields, and more detailed processing is usually required to achieve these translation requirements. In this regard, Langboat has done a lot of optimization work on the vertical domain translation engine, including rapid domain adaptation technology, semi-supervised training technology, and term recognition and translation technologies. In natural language processing, the semantics of a word is usually related to its context or domain. For example: in the field of construction machinery, the word "jacks" should mean "jack", but it also has other meanings such as "socket, jack". How to achieve accurate translation of technical terms in specific fields and improve translation experience, Very important in vertical domain translation engines. A simple and effective technique is to introduce a term translation module, which provides a term dictionary as prior knowledge to achieve accurate translation. In use, for example, when a translator is translating, he can specify that a certain word should only be translated into the specific meaning he wants. Two typical approaches to achieve term translation are: slot replacement based approach and term injection based approach. Based on the slot replacement method, the terms in the sentence are replaced with variable slots before the sentence enters the translation model, and the translation of the term is filled back into the corresponding slot after the model is translated, so as to obtain the final translation. Term injection-based methods select translations corresponding to terms by training a model.

In the financial field, comparing the results of Langboat Financial Translation Engine with two well-known engines, we can see that after specific optimization in the financial field, Langboat Financial Translation Engine is more accurate in translating financial terms.
English-Chinese translation:


Chinese-English translation:


04 Langboat Machine Translation Platform#
Langboat has established a machine translation platform to train multilingual translation models through large-scale basic data. On this basis, it has established translation engines in various vertical fields through data and technologies in vertical fields.
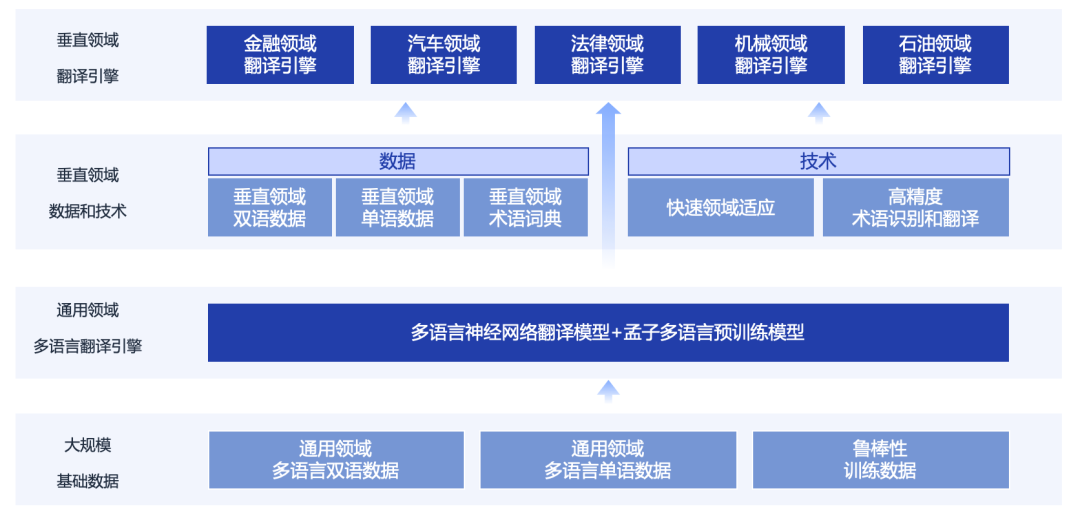
At present, Langboat Technology has cooperated with Transn, and has established general-purpose translation and translation engines in many fields, including machinery, automobiles, engineering, law, petroleum, contracts, electric power and many other fields, reaching the world's leading level.
05 Outlook for the future work of machine translation#
Langboat Technology's machine translation research has achieved exciting results. On this basis, there are still many future work directions to look forward to.
- Translation of resource-scarce languages: Existing technologies rely on a large number of bilingual parallel corpora. In order to improve the translation quality of resource-scarce language pairs (such as Indonesian-Chinese), it is necessary to study multilingual pre-training models or other technologies.
- Improve industry translation: Due to the different expression styles of different industries, in order to meet professional needs on the basis of a general model, it is necessary to enrich the corpus for each industry, identify terms and translate terms at the same time.
- Training and running costs: Model training requires high-performance computing resources, and in order to support running on small devices (such as mobile terminals), model compression is required.
- Cross-sentence-level translation: At present, translation is carried out sentence by sentence. In order to maintain the coherence of translation, it is still necessary to improve the capabilities of resolution of reference, gender, number, and case consistency to solve the problem of cross-level modeling.
In the future, based on its own technological advantages, Langboat will gradually build a multilingual translation engine. It also looks forward to greater breakthroughs in machine translation in the future with the joint cooperation and efforts of academia and industry. Langboat will always adhere to technological innovation, promote technological progress and implementation in the field of artificial intelligence, and make greater contributions to industrial upgrading, high-quality social and economic development, and national prosperity.
References:#
[1] 肖桐,朱靖波,《机器翻译:基础与模型》, 电子工业出版社, 2021.
[2] Bahdanau D, Cho K H, Bengio Y. Neural machine translation by jointly learning to align and translate[C]. ICLR 2015.
[3] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]//Advances in neural information processing systems. 2017: 5998-6008.
[4] Edunov S, Ott M, Auli M, et al. Understanding Back-Translation at Scale[C]//Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 2018: 489-500.
[5] Wu L, Wang Y, Xia Y, et al. Exploiting monolingual data at scale for neural machine translation[C]//Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019: 4207-4216.
[6] Dinu G, Mathur P, Federico M, et al. Training Neural Machine Translation to Apply Terminology Constraints[C]//Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019: 3063-3068.
[7] Song K, Zhang Y, Yu H, et al. Code-Switching for Enhancing NMT with Pre-Specified Translation[C]//Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019: 449-459.
[8] Liu Y, Gu J, Goyal N, et al. Multilingual Denoising Pre-training for Neural Machine Translation[J]. Transactions of the Association for Computational Linguistics, 2020, 8: 726-742.
[9] Xue L, Constant N, Roberts A, et al. mT5: A Massively Multilingual Pre-trained Text-to-Text Transformer[C]//Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2021: 483-498.
Products
Business Cooperation Email
Address
Floor 16, Fangzheng International Building, No. 52 Beisihuan West Road, Haidian District, Beijing, China.
© 2023, Langboat Co., Limited. All rights reserved.
Large Model Registration Code:Beijing-MengZiGPT-20231205
Business Cooperation:
bd@langboat.com
Address:
Floor 16, Fangzheng International Building, No. 52 Beisihuan West Road, Haidian District, Beijing, China.
Official Accounts:

© 2023, Langboat Co., Limited. All rights reserved.
Large Model Registration Code:Beijing-MengZiGPT-20231205


